Introduction
When it comes to audio, we are spoiled with an abundance of riches. DACs, amps, headphones have gotten so much better over the past 15 years, it’s hard to imagine that this was sometimes considered a “solved problem”. At the same time, prices have gotten incredibly low.
For example, 15 years ago if you wanted a DAC + headphone amp having studio reference quality, the Benchmark DAC or Grace M920 were two of your only options, both cost $1 – $2 kilobucks which would be about 50% more in today’s dollars. Back in ’99 I bought a Headroom Maxed out Home amplifier that cost $1000. It was the best headphone amp of its time, both in measurements and subjective listening. Today for $150 you can get amps having even cleaner measurements and more power. That’s only 1/10 of the inflation adjusted equivalent price.
Summary
TLDR: The Topping EX5 is functionally comparable to those Benchmark and Grace devices, and equal or superior in terms of measurements. It retails for $350, I bought it on sale for $300, which is about 1/10 of their equivalent price. This is my first piece of “Chi-Fi” (Chinese Hi-Fi) equipment. Here are my impressions having used it daily for a few weeks, including bench testing with Room EQ Wizard.
Good Stuff
- Excellent measured performance
- Great subjective sound quality: clean, detailed, neutral
- Solid build quality
- Low price
Bad Stuff
- The manual has serious errors (mislabeled digital filters)
- Factory support is poor to entirely lacking (no responses to support queries)
- It has obvious software bugs (the display shows the wrong sampling rate)
Those last 2 are double-threat. I can live with software bugs if the company has great support, as they will fix the bugs. I can live with poor support if the device works seamlessly, as I won’t need support. But a buggy device combined with poor support is a “no-go” for me.
Overview
First, check out Amir’s detailed review & measurements on ASR. The EX5 is a well engineered device having excellent measured performance.
What is the EX5?
- DAC supporting PCM and DSD formats
- Select between 4 inputs
- Volume control
- Line-level preamp
- Headphone amp
Inputs:
- SPDIF Coax
- SPDIF Toslink
- USB
- Bluetooth
Outputs:
- Line: Balanced XLR and SE RCA
- Headphone: Balanced 4-pin and SE 1/4″ plug
Key EX5 features
- Compact all-in-one device: DAC, preamp, headphone amp
- Reference quality audio: digital & analog
- Internal power supply: no wall-wart
- Digital volume control
- Perfect channel balance at all levels
- Preserves high SNR even at low volumes: 90 dB SNR @ 50 mV
- User-selectable digital filters: choose from 7!
- linear vs. minimum phase
- sharp vs. slow attenuation
Case, Knobs & Quality
Overall the EX5 feels like a high quality piece of kit. The case is heavy & neat, the connectors feel solid, the display is evenly lit, the volume knob has a smooth clicky feel.
The volume knob is a rotary encoder that also serves as a push-button. I’ve seen rotary encoders start to fail in other equipment I own. After a few years their click action became glitchy, as you turn it up it sometimes turns down, etc. Cleaning the internal contacts with electrical spray helps but is temporary as the problem eventually recurs. I hope the EX5 rotary encoder does not suffer the same fate.
The display has 3 brightness levels and is always on. It has an auto-dim feature in which the display goes mostly dark after 30 seconds, showing only the selecting input. This is my preferred mode, as it hides the incorrect display of sample rate.
In use, the EX5 gets warm but not hot. Just a touch warmer than my JDS Atom amp. The EX5 case is solid metal with no vents on the bottom, sides or top. It feels like the solid metal case serves to dissipate its internal heat.
Volume Control
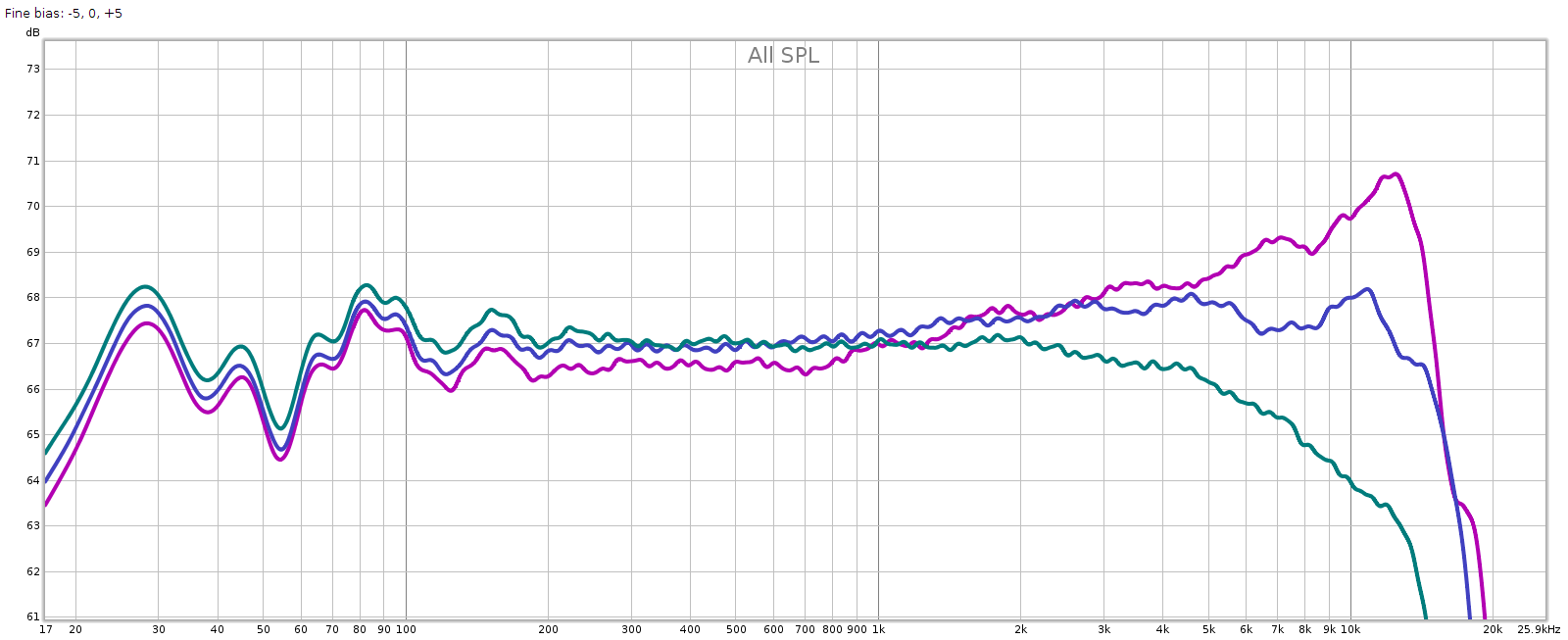
The EX5 has 2 gain modes: low (standard) and high, which is 10 dB louder. Its volume control has 100 steps. To assess how the steps interact with volume level, I measured the output level using white noise:
- 100: max
- 60: -20 dB
- From 60 – 100, each step is 1/2 dB
- 30: -50 dB
- From 30 – 60, each step is 1 dB
- 20: -68 dB
Low gain has plenty of volume for my HD-580 and LCD-2F headphones. I typically listen around setting 50-60 with high dynamic range music having low average levels. This is about 30 dB below max. So I’d be using lower levels for rock or modern music which is dynamically compressed having louder average levels.
Note: at low gain, 0 dB is 4.1 Vrms. Volume setting 50 is 30 dB quieter, which is 3.16% of that, or 130 mV. This drives the LCD-2F to 87.5 dB SPL for the loudest peaks of the music. But it’s really 6 dB quieter because my DSP for EQ drops the overall levels by 6 dB. So my typical listening puts the loudest musical peaks at around 82 dB SPL.
Wish List
The EX5 packs a lot of functionality in a compact box. Yet the challenge of single-box audio devices is they can work so well they leave me wanting just a bit more. Here’s what I wish the EX5 also did…
DSP
It would be great to have parametric EQ and crossfeed for headphones. Of course, it would take some creative thinking to do this with the EX5’s single knob/button. Without it, you must find a way to apply whatever DSP you want, upstream from the EX5.
Analog Input
The title speaks for itself. The EX5 has a great little built-in preamp / headphone amp and it would be really useful to have an analog input. Yet I understand why they didn’t do this. Since the EX5 has a digital volume control, they would have to significantly change the device in order to accept analog inputs.
Bugs / Problems
No device is perfect. Here are the issues I found with the EX5.
Sample Rate Display
The biggest problem I found with the EX5 is the display. When using SPDIF input over toslink or coax, the display always shows 44.1 (sometimes 48) regardless of the actual sample rate. Sometimes it shows the right sample rate, usually it does not and gets stuck at 44.1. For example, I measured the EX5 at 44.1, 48, 88.2, 96, 176.4 and 192. For the entire time the display showed 44.1 even when it was clearly operating at these other rates. As I type these words I’m listening to Sibelius Symphony #1 at 96 kHz yet the EX5 display is showing 44.1. One when I played 96k content the display showed 48.
This happens over digital coax or toslink from my Juli@ sound card, and over the toslink output of my Behringer DEQ2496. My other DACs (Oppo HA-1 and Corda Soul) show the proper sample rate from these devices.
I reported this to Topping on their support web site and got no reply. And tagged them on the ASR forum, no reply. There is essentially no factory support for this device.
I speculate that Topping designed this device to be plugged into Windows or Mac computers, and they rely on their custom device driver to set the displayed sample rate. In other words, the EX5 doesn’t show you the actual sample rate at which it is working, it shows you whatever rate the driver tells it to display, and defaults to 44.1 or 48.
Auto-Mute
The EX5 auto-mutes if the digital audio input has a quiet L channel. The delay depends on sample rate: about 5 secs at 192k, about 25 secs at 44.1k. This is not documented and could cause frustrating lost time chasing down ghosts if you don’t know about it.
Balanced – Not Really
The EX5 has balanced outputs, both line (XLR) and headphone (4-pin). The XLR line out has twice the voltage of the RCA (4.3 Vrms vs. 2.1), so it appears to be fully balanced (differentially signalled). But the headphone output has the same voltage output on either (5.9 Vpp with low gain, 18.3 Vpp on high), so it’s not fully balanced. The balanced headphone outputs probably use separate grounds for the L and R channels, as the balanced channel separation is higher (99 vs. 88 dB).
Note: the headphone output is given as Vpp, so multiply by 0.7 to get Vrms. Thus for low gain, 5.9 Vpp –> 4.1 Vrms and for high gain, 18.3 Vpp –> 12.6 Vrms.
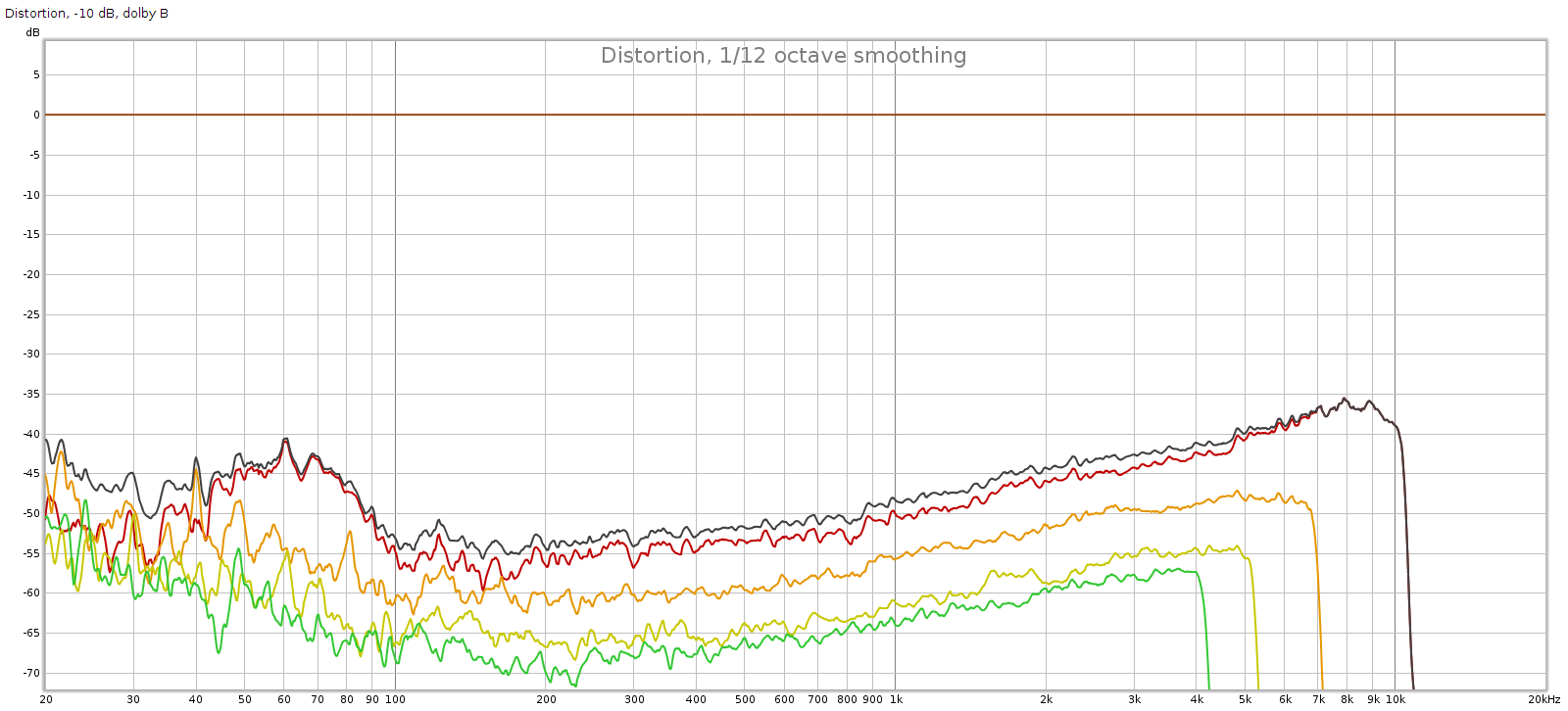
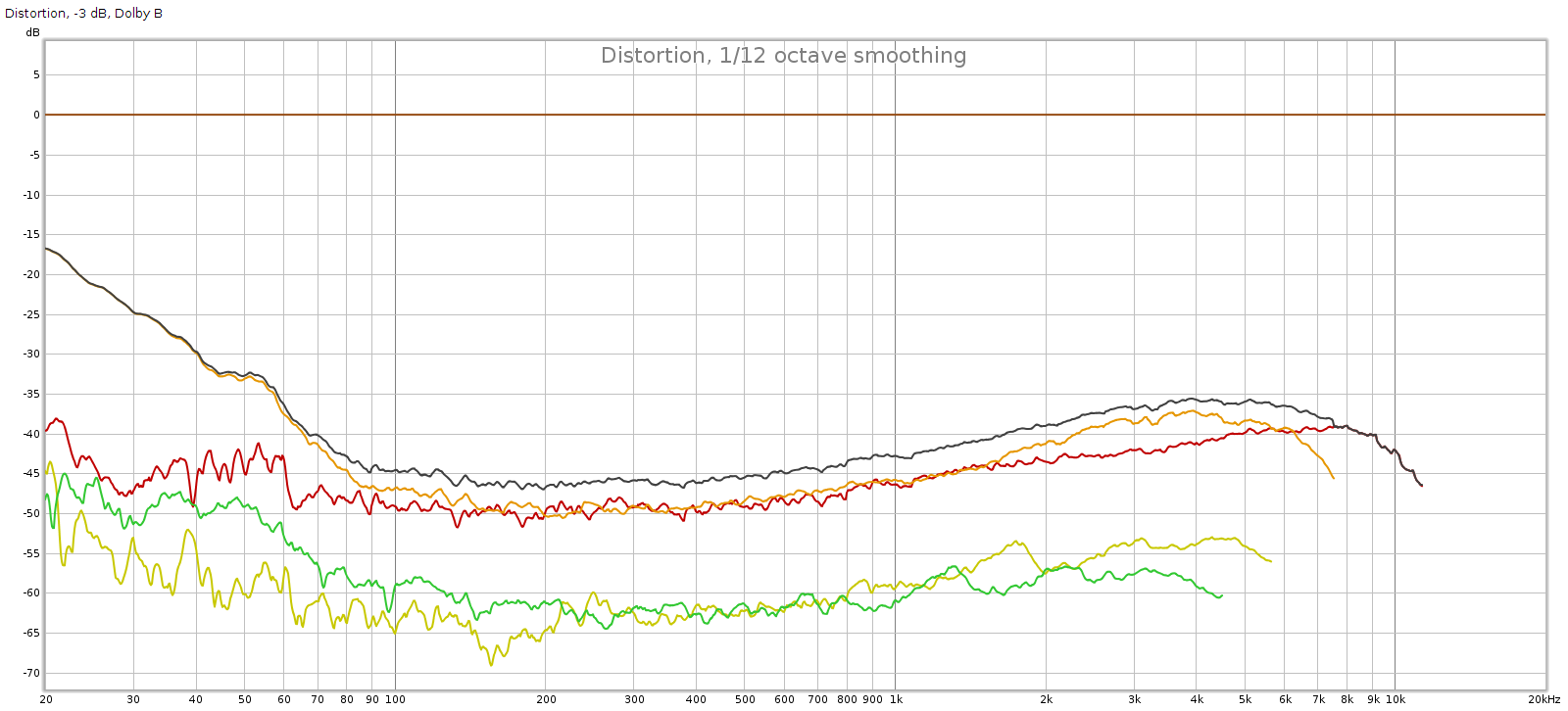
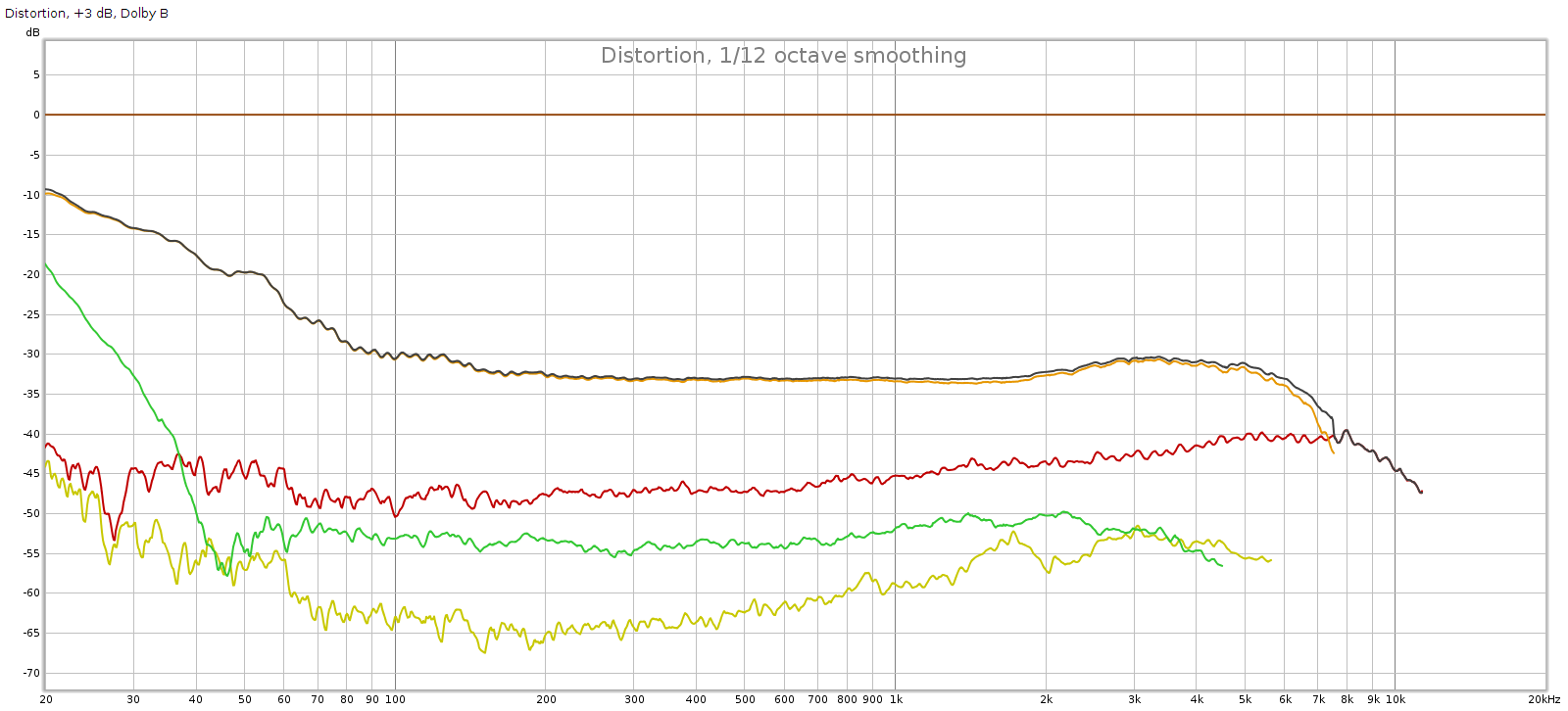
Measurements
I measured the EX5 using Room EQ Wizard and my Juli@ PC sound card. This equipment is pretty basic so I can’t measure the full extent of the EX5 sound quality. But it does enable me to test some of the basics.
Here I will focus on frequency response and the digital filters. This is for 2 reasons:
- The EX5 manual is wrong
- This is easy to measure
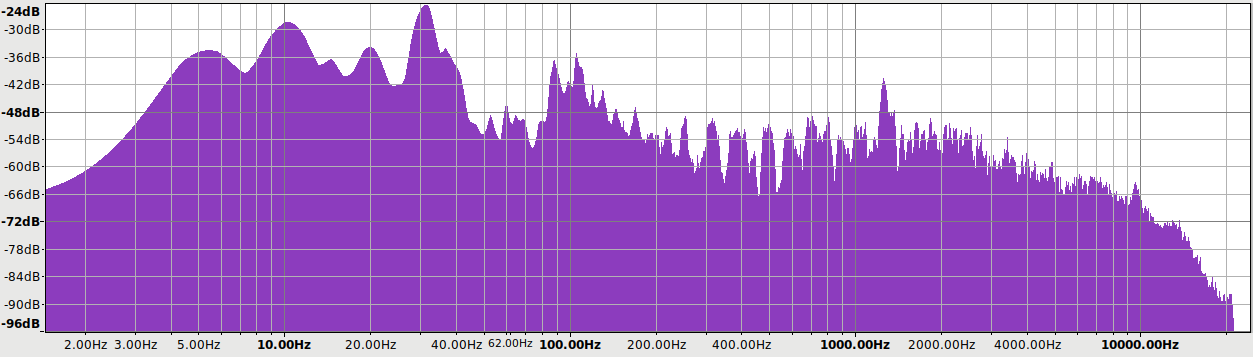
Here’s the frequency response of the EX5 digital filters at 44.1 kHz sampling:
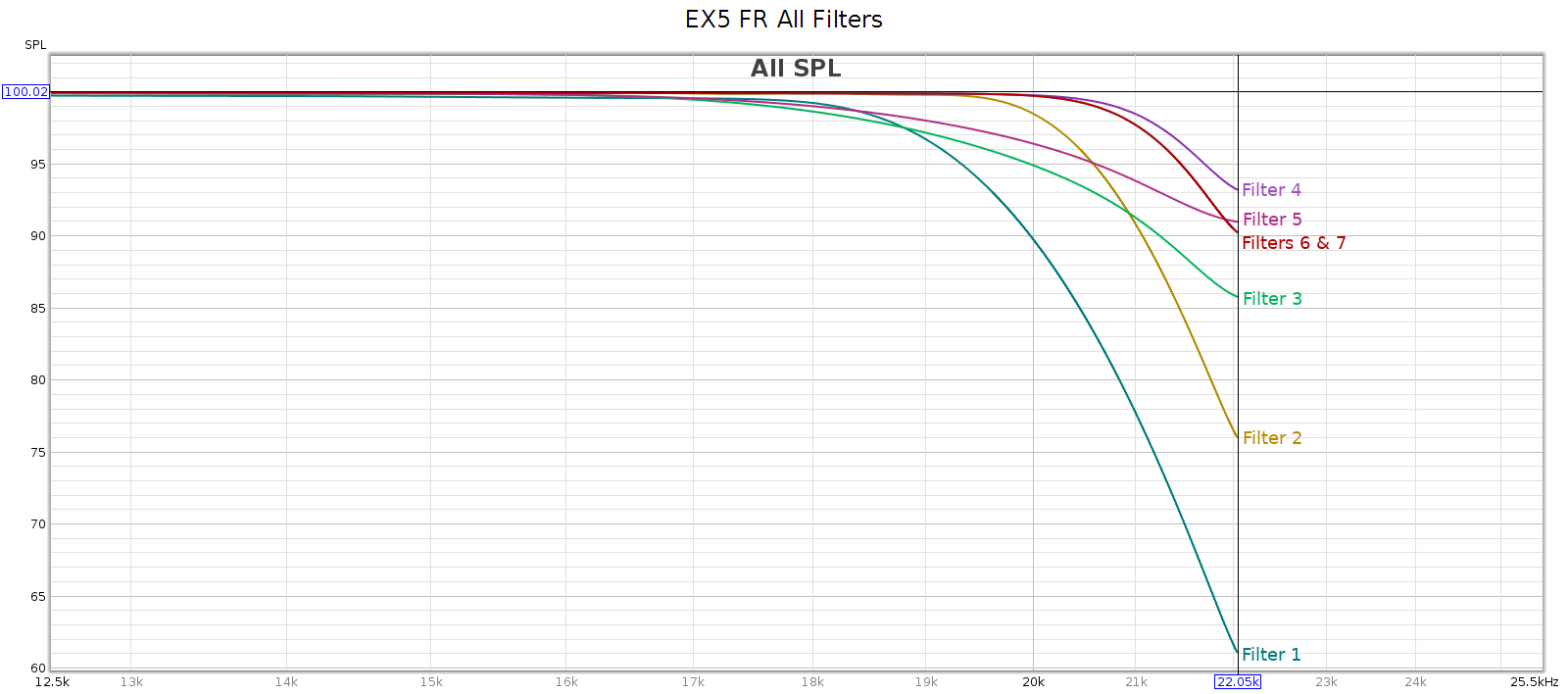
Filters 4, 6 and 7 are a bit lazy and don’t fully attenuate until 24.1 kHz. This is incorrect, yet benign.
Filters 3 and 5 are very lazy and don’t fully attenuate until 28 kHz. This can be a problem.
Filters 1, 3 and 4 are minimum phase.
Filters 2, 5, 6, 7 are linear phase.
Filters 6 and 7 are identical in my measurements (both response & phase).
In summary:
- Filter 2 is the most correct, but it is not perfect
- Fully attenuated by Nyquist (surprisingly rare, but welcome)
- Linear phase (flat phase vs. frequency)
- It has a bit of ripple, not perfectly smooth
- It has just a tad of passband attenuation: -1.5 dB @ 20 kHz
- Filter 6/7 is as good as #2, with different tradeoffs
- Fully attenuated by 24.1 kHz, thus any aliasing is above 20 kHz
- Linear phase (flat phase vs. frequency)
- No ripple – perfectly smooth response
- No passband attenuation: -0.3 @ 20 kHz
- Filter 4 is the best minimum phase filter
- Fully attenuated by 24.1 kHz, thus any aliasing is above 20 kHz
- Phase rises smoothly to +210* at 15 kHz, then drops to 0* at 21 kHz.
- No ripple – perfectly smooth response
- No passband attenuation: -0.2 @ 20 kHz
Put in reverse, why not use the other filters?
- Filter #1 has significant passband attenuation: -10 dB @ 20 kHz
- Filters #3 and #5 don’t attenuate until 28 kHz, thus leak high frequencies that can alias down to 16 kHz
How is the manual wrong? It gets 6 of the 7 filter descriptions wrong.
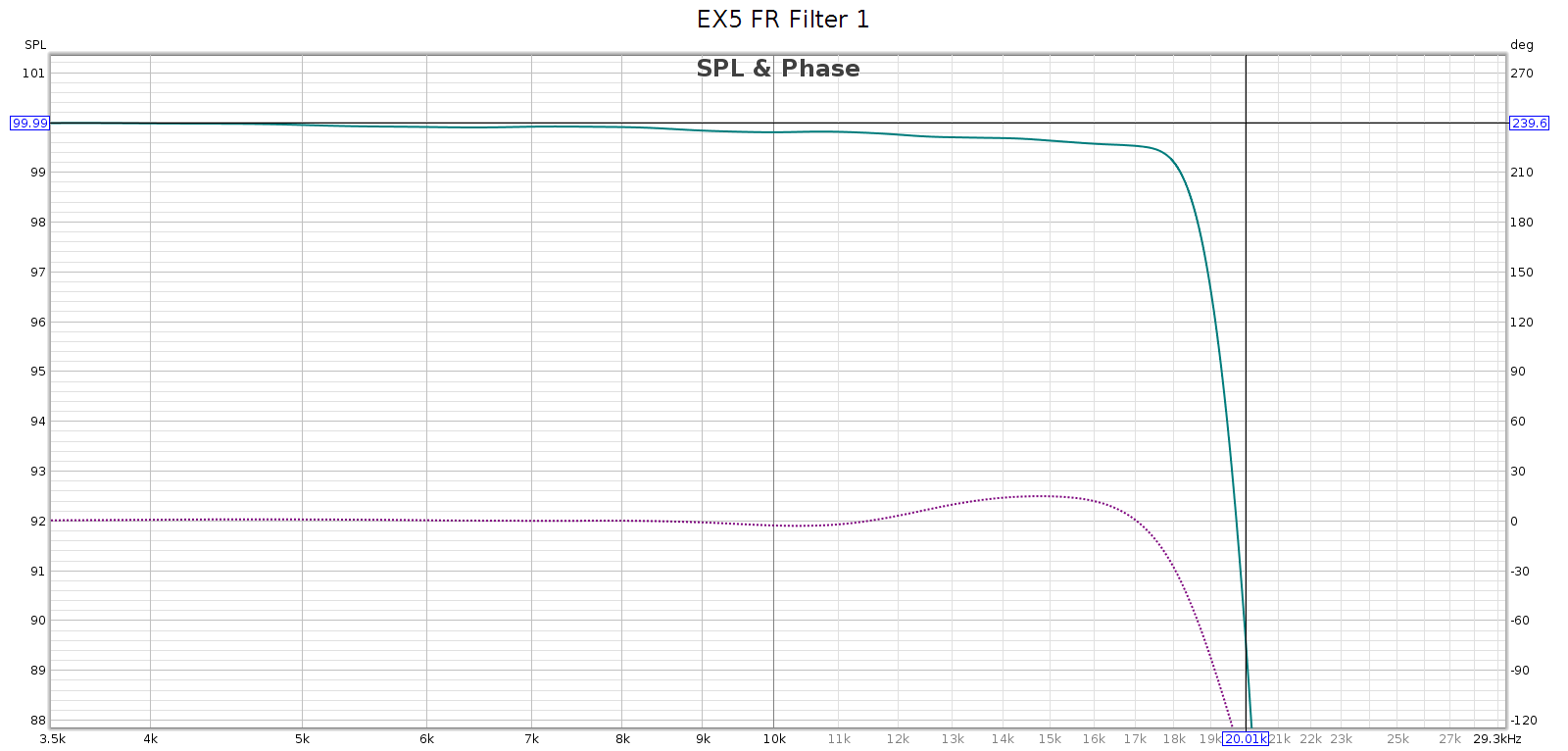
- It labels #1 as fast rolloff apodizing, which is wrong
- It rolls off slowly with significant passband attenuation, -10 dB @ 20 kHz
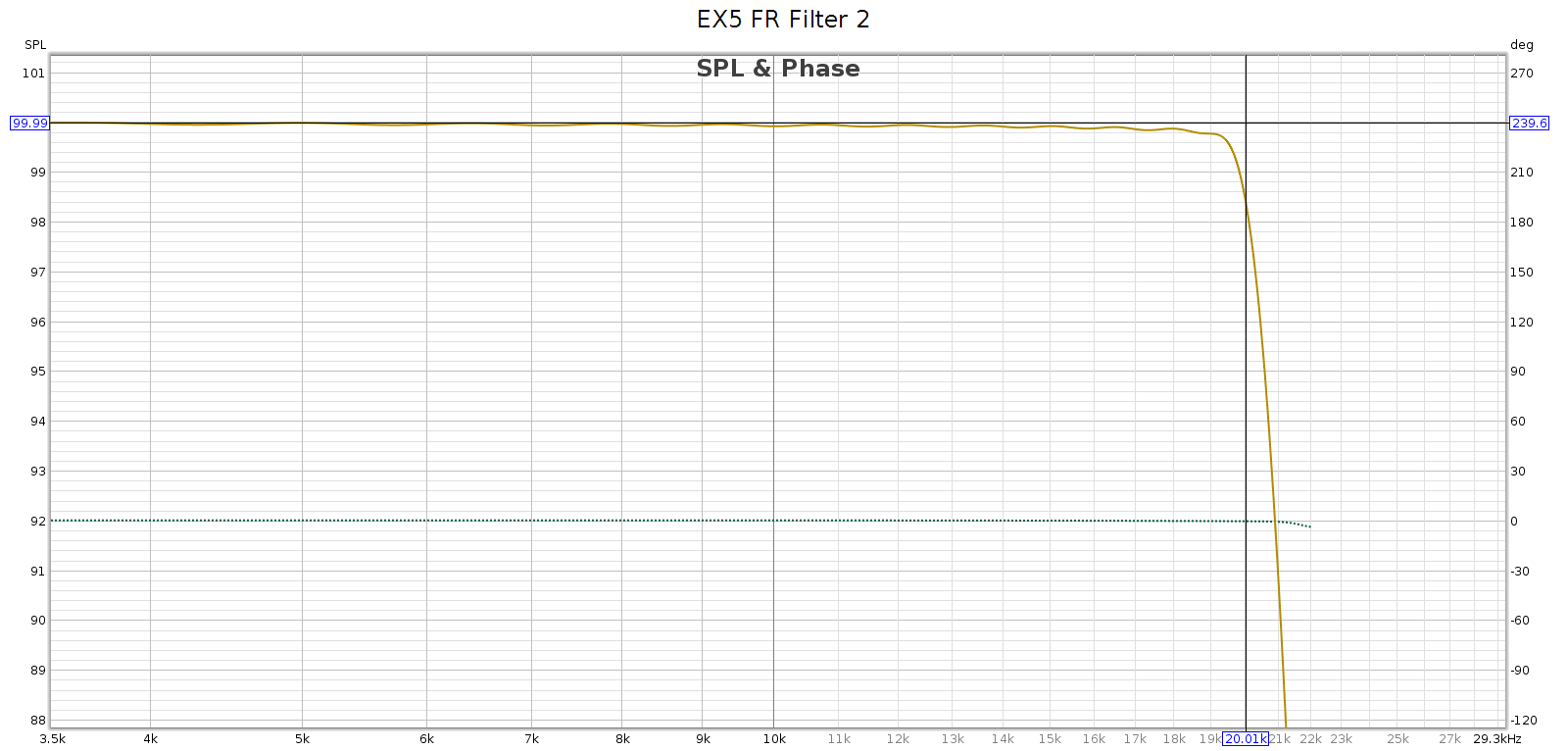
- It labels #2 as slow rolloff minimum, which is wrong
- It rolls of sharply with almost no passband attenuation
- It is linear phase, not minimum phase
- It labels #3 as fast rolloff minimum, which is wrong
- It rolls off slowly with significant passband attenuation: -5 dB @ 20 kHz
- It labels #4 as slow rolloff linear, which is wrong
- It rolls off sharply with no passband attenuation
- It is minimum phase, not linear phase
- It labels #5 as fast rolloff linear, which is wrong
- It rolls off slowly with significant passband attenuation: -3.6 dB @ 20 kHz
- It does not fully attenuate until 28 kHz
- It labels #6 as brick-wall, which is correct!
- It has no passband attenuation, fully attenuates by 24.1 kHz, and is linear phase
- It labels #7 as fast rolloff corrected minimum, which is wrong
- This filter is identical to #6, and is linear phase
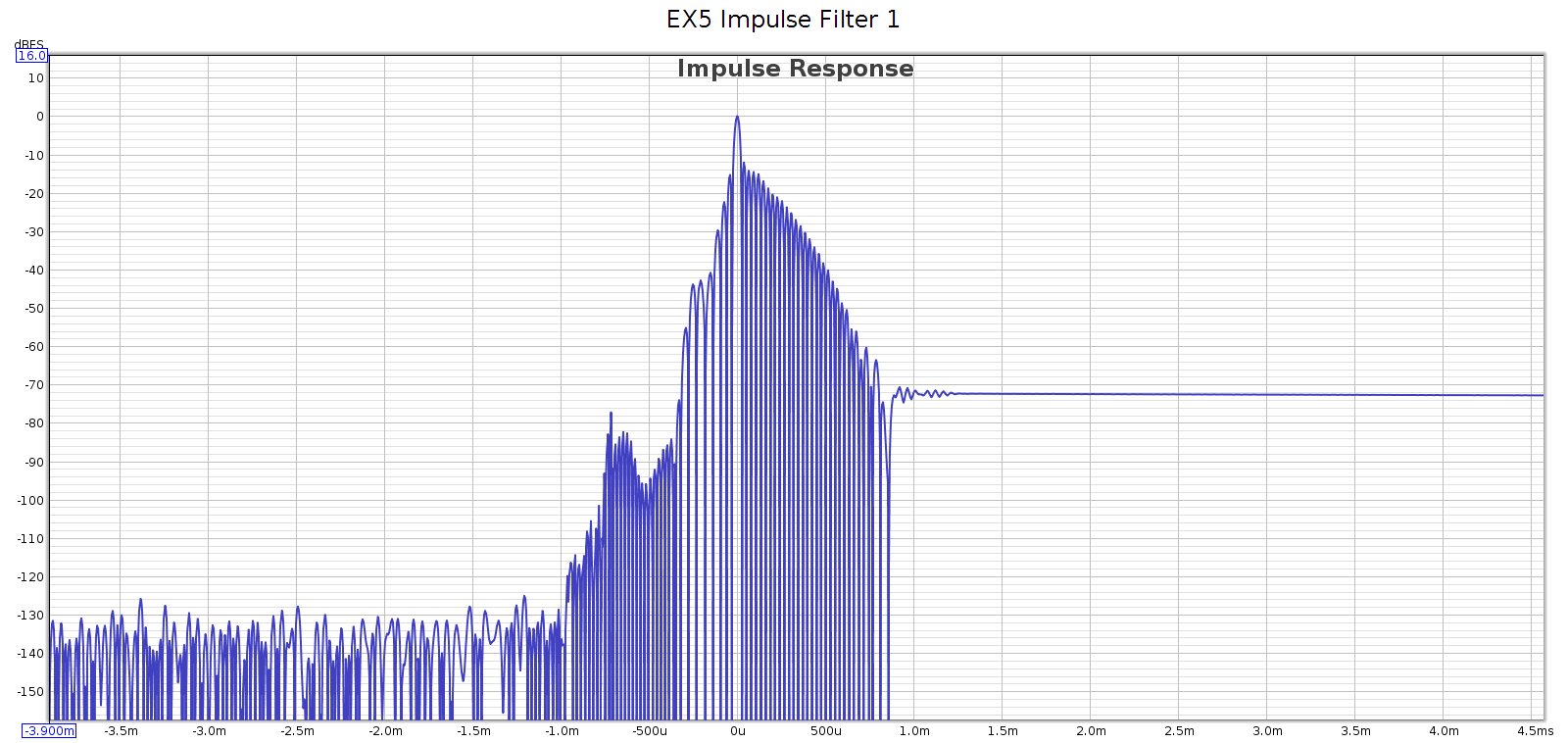
Measured at 44.1 kHz, here are the frequency response, phase, and impulse response of each of these filters. In each graph, the cursor marks the flat response corner @ 20 kHz. Below, note that the minimum phase filters have non-flat phase and asymmetric impulse response.
Filter 1
Filter 2
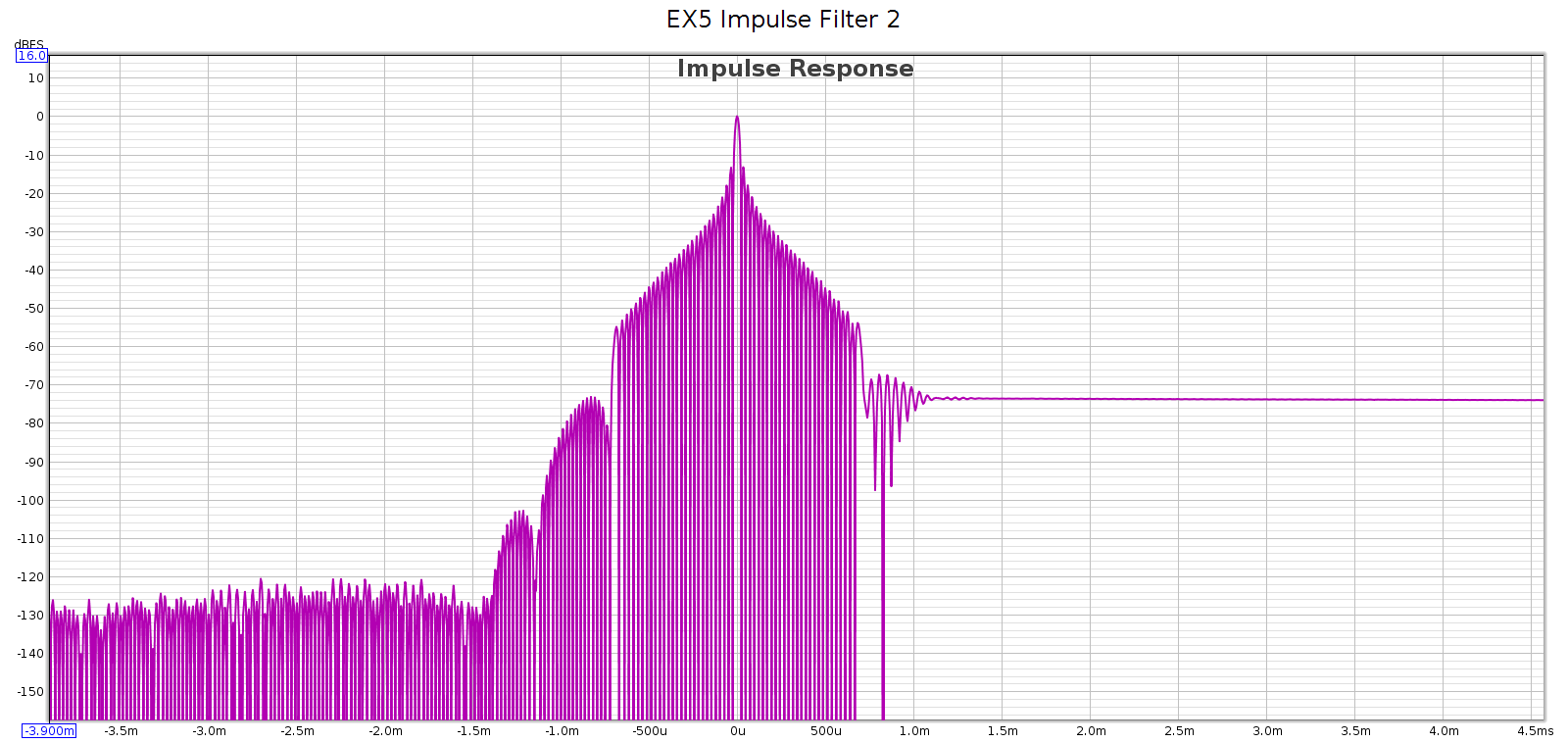
Filter 3
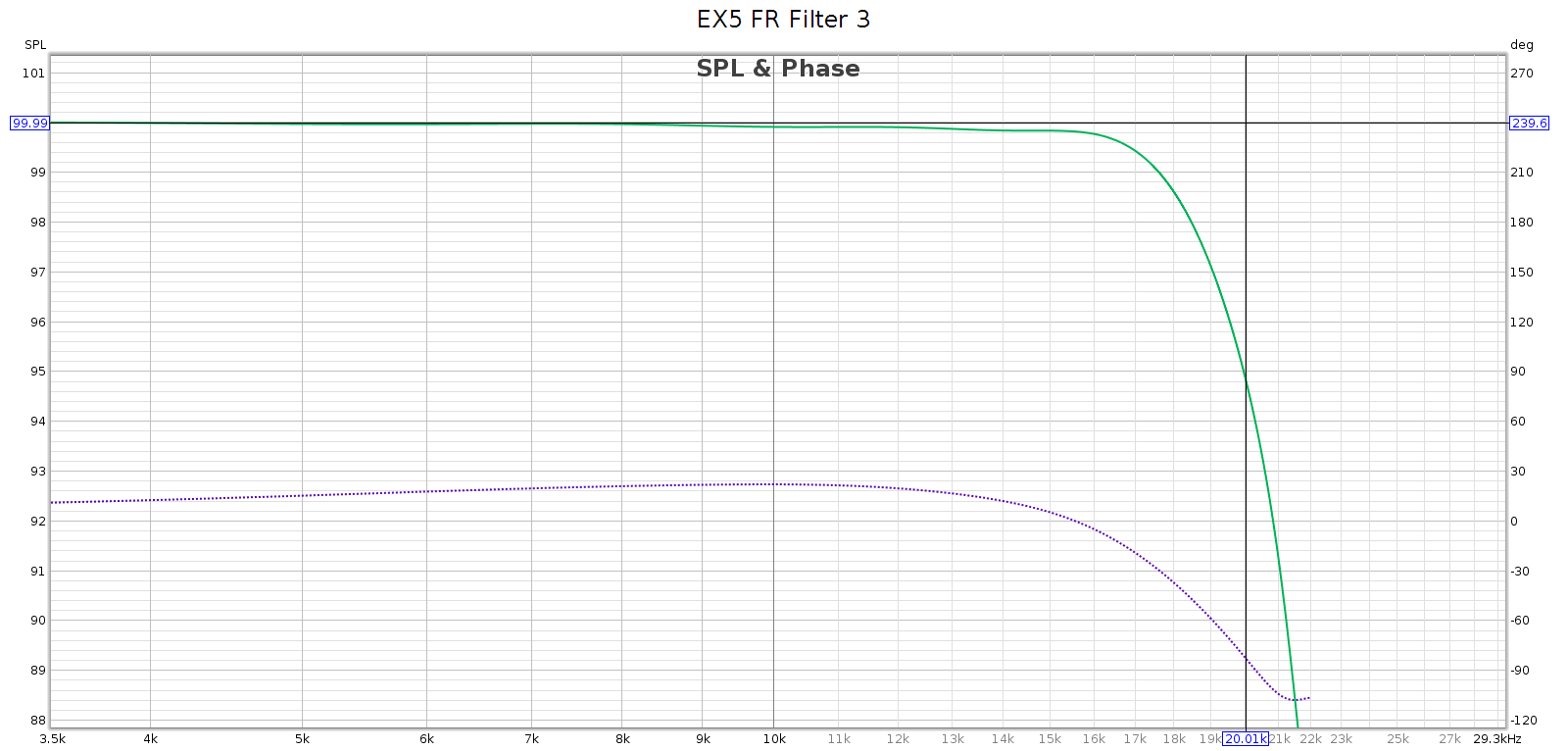
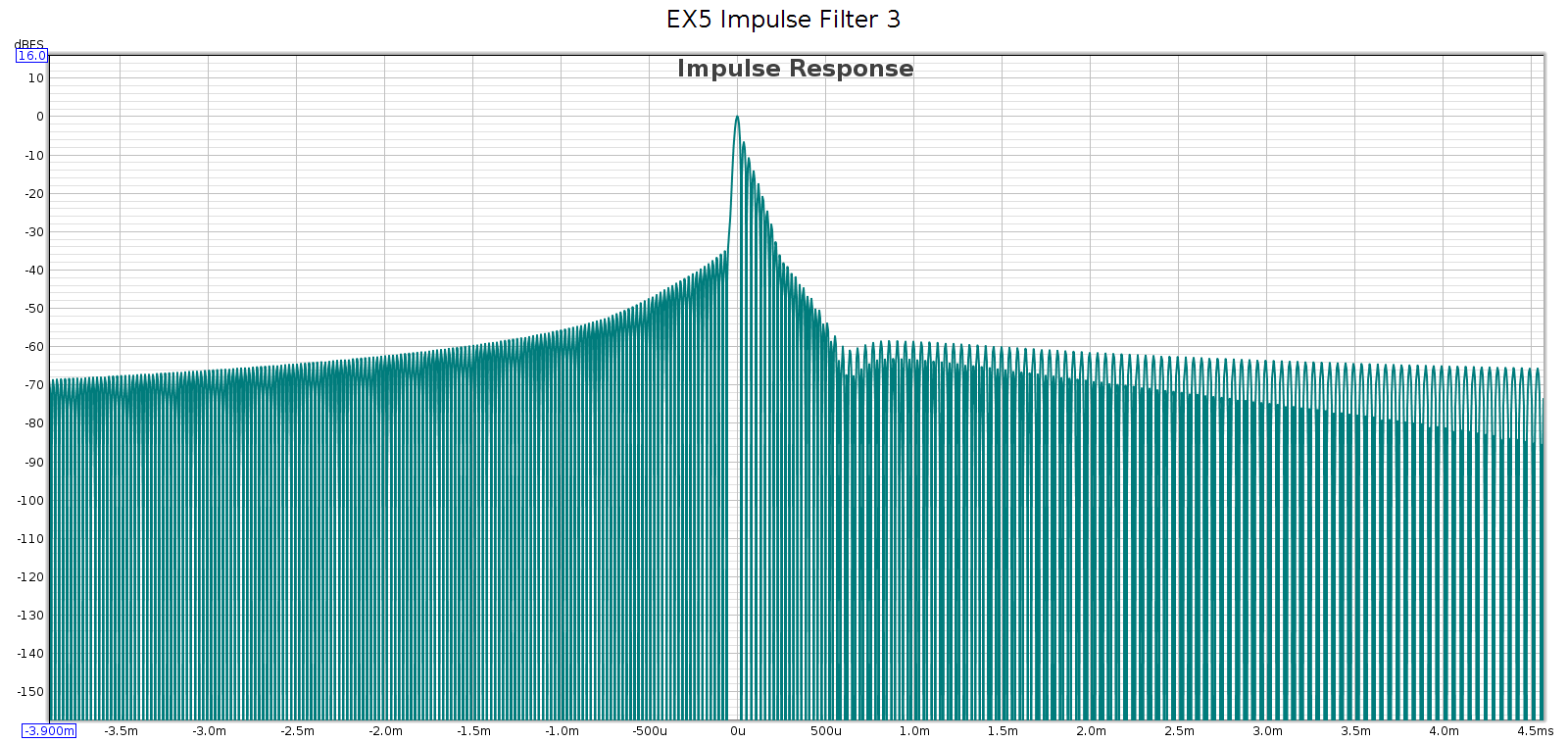
Filter 4
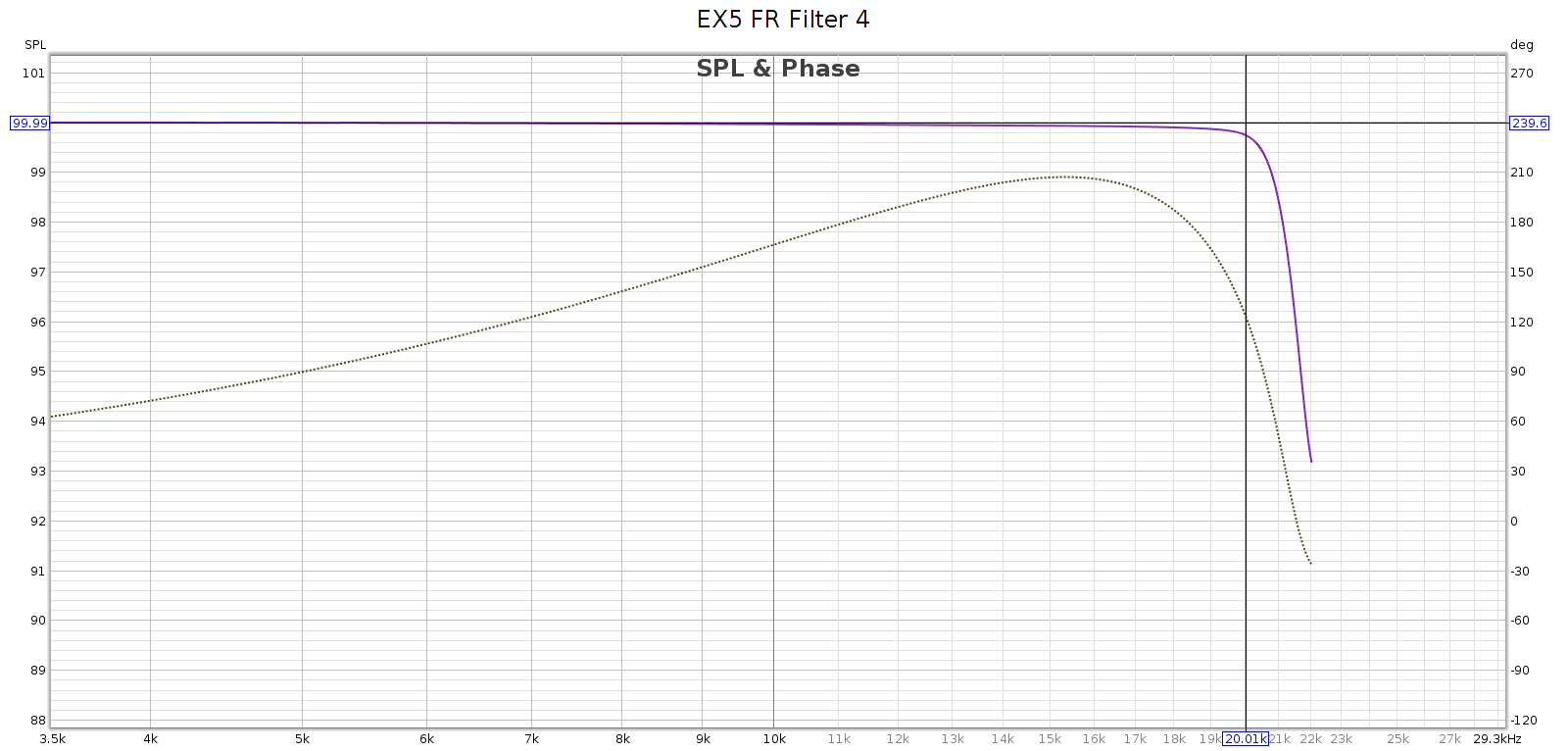
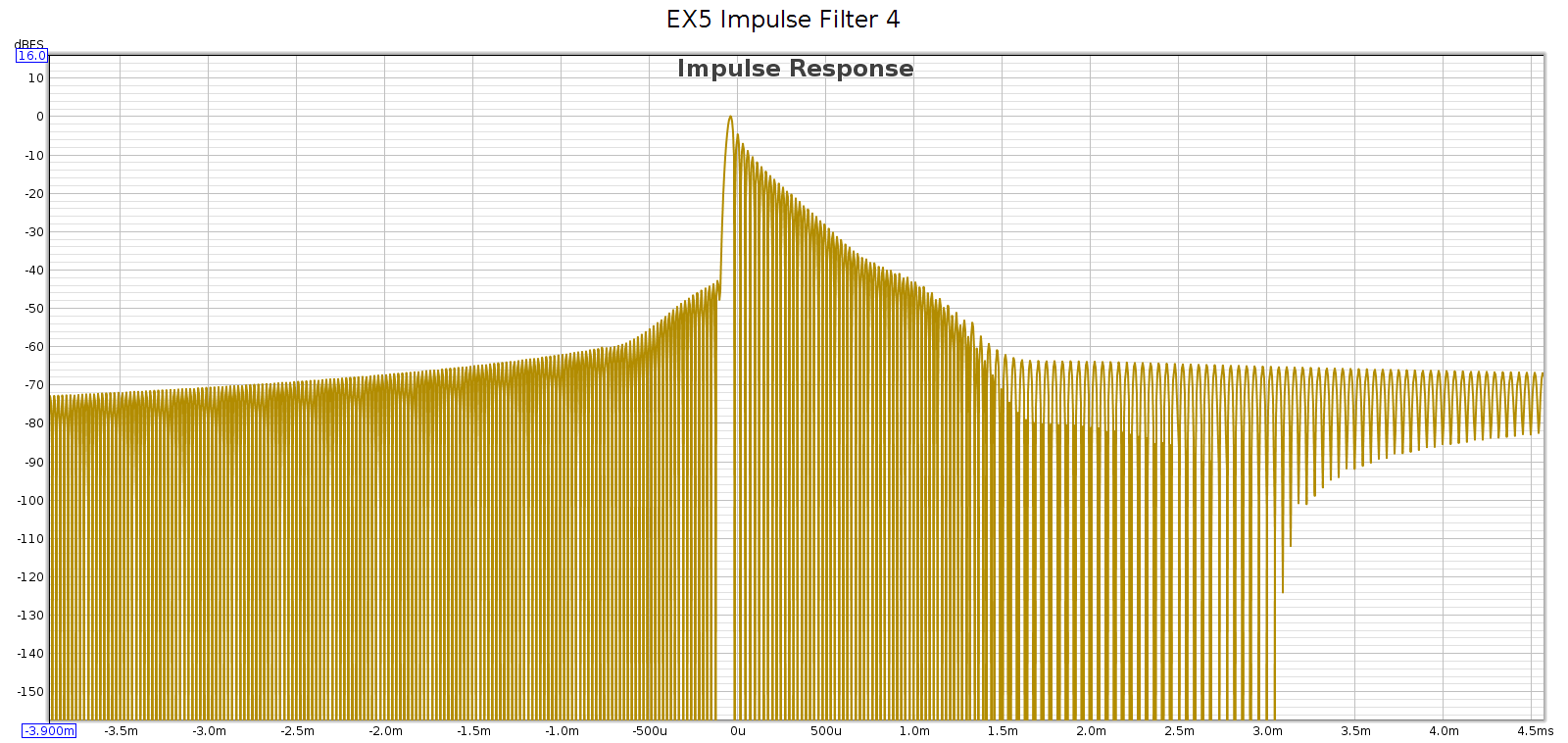
Filter 5
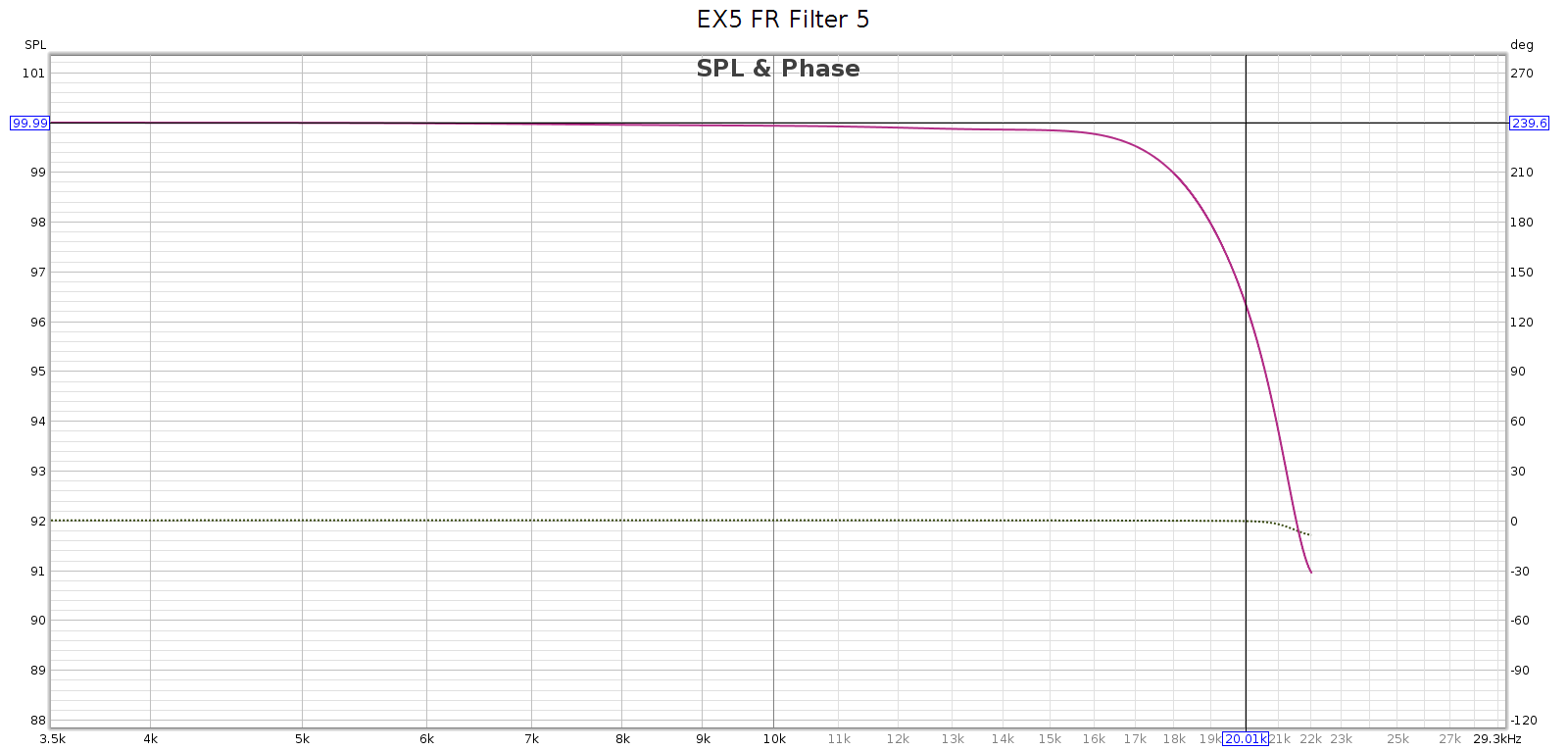
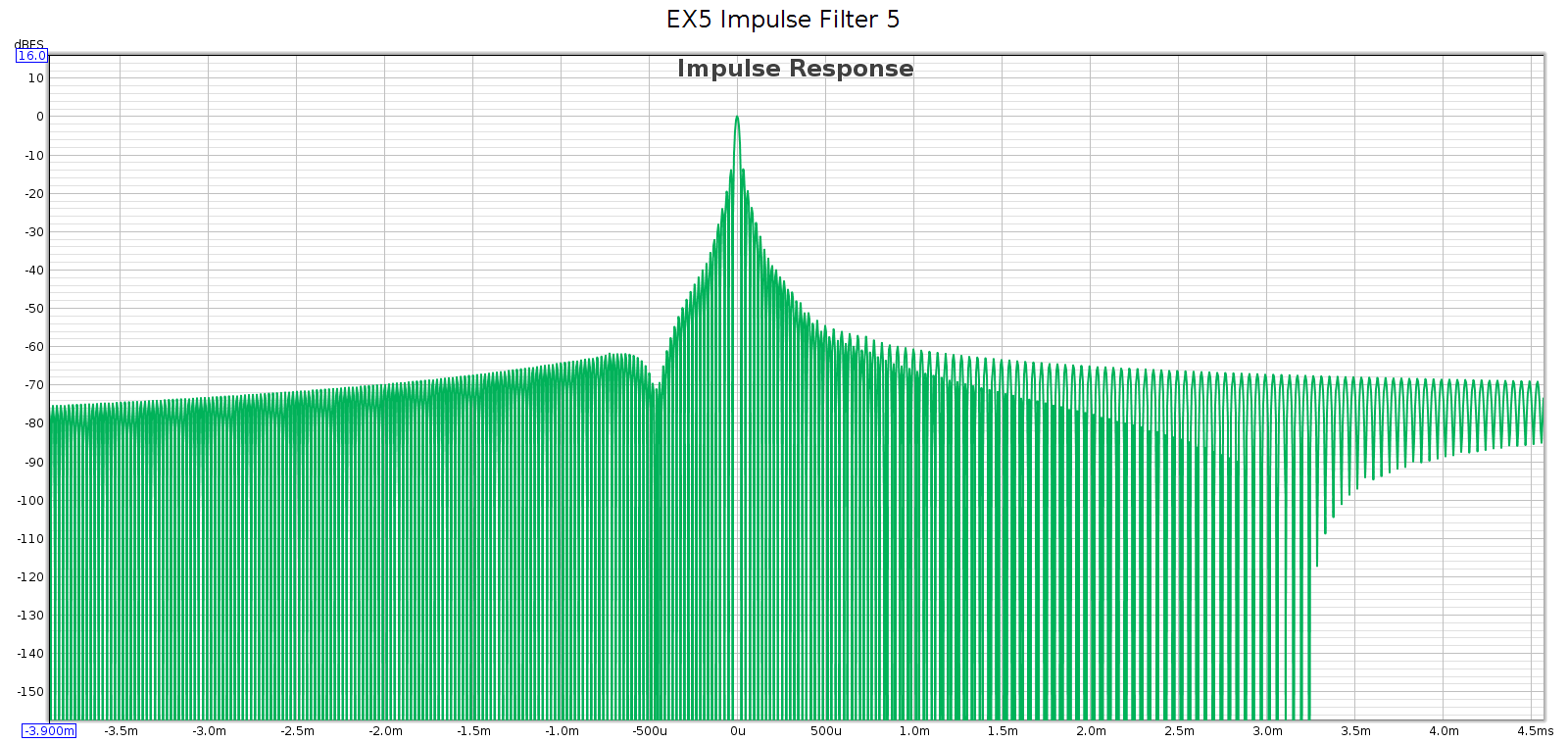
Filter 6
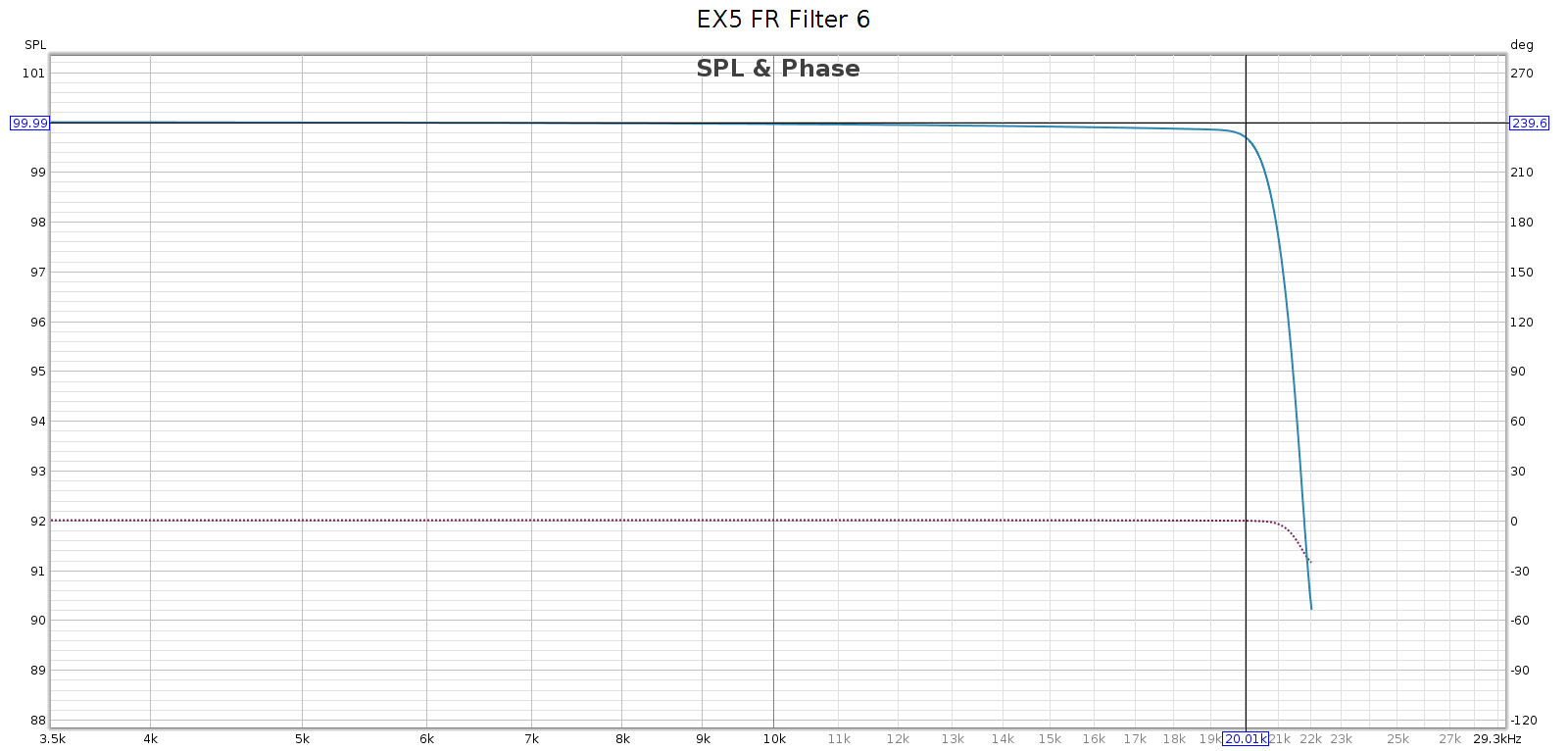
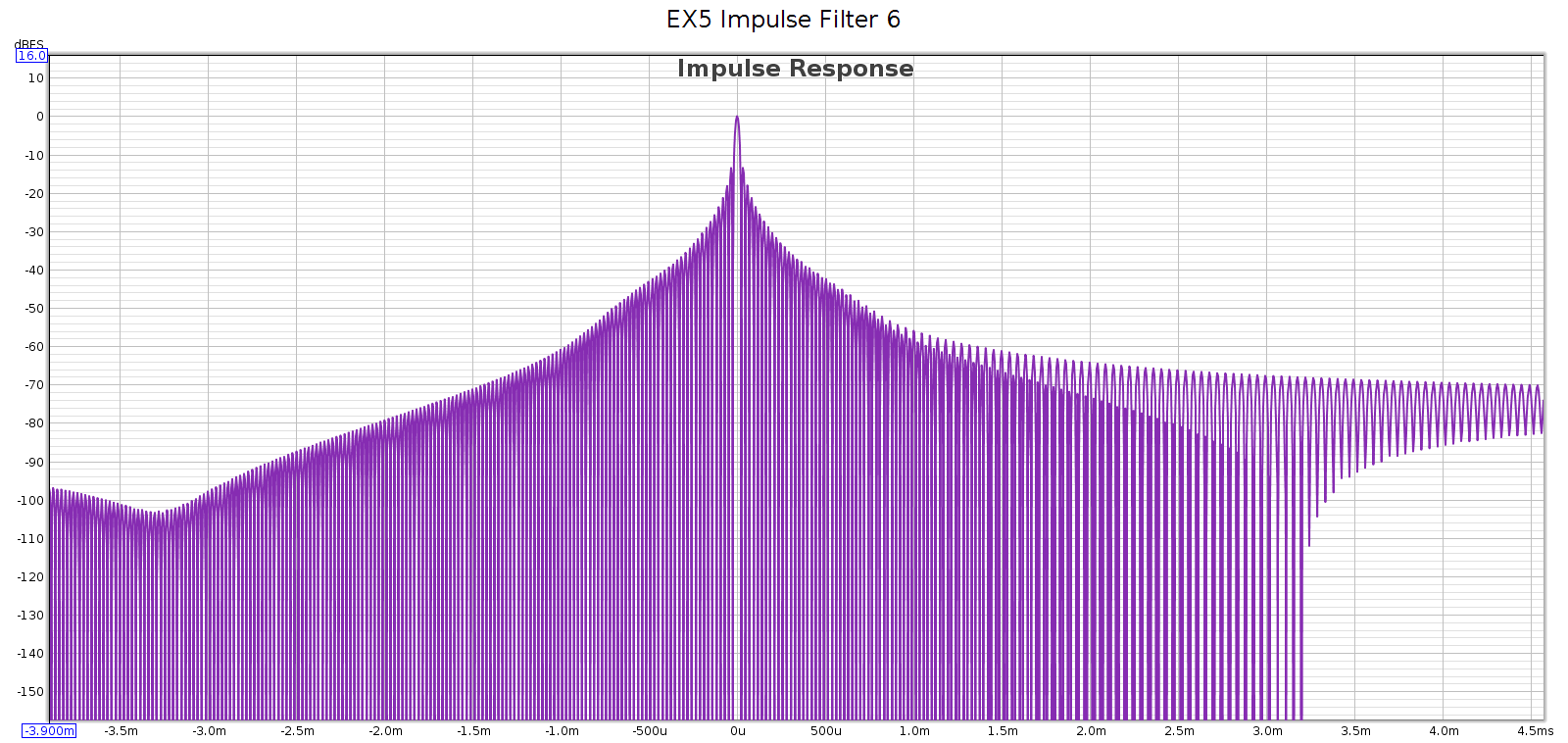
Filter 7
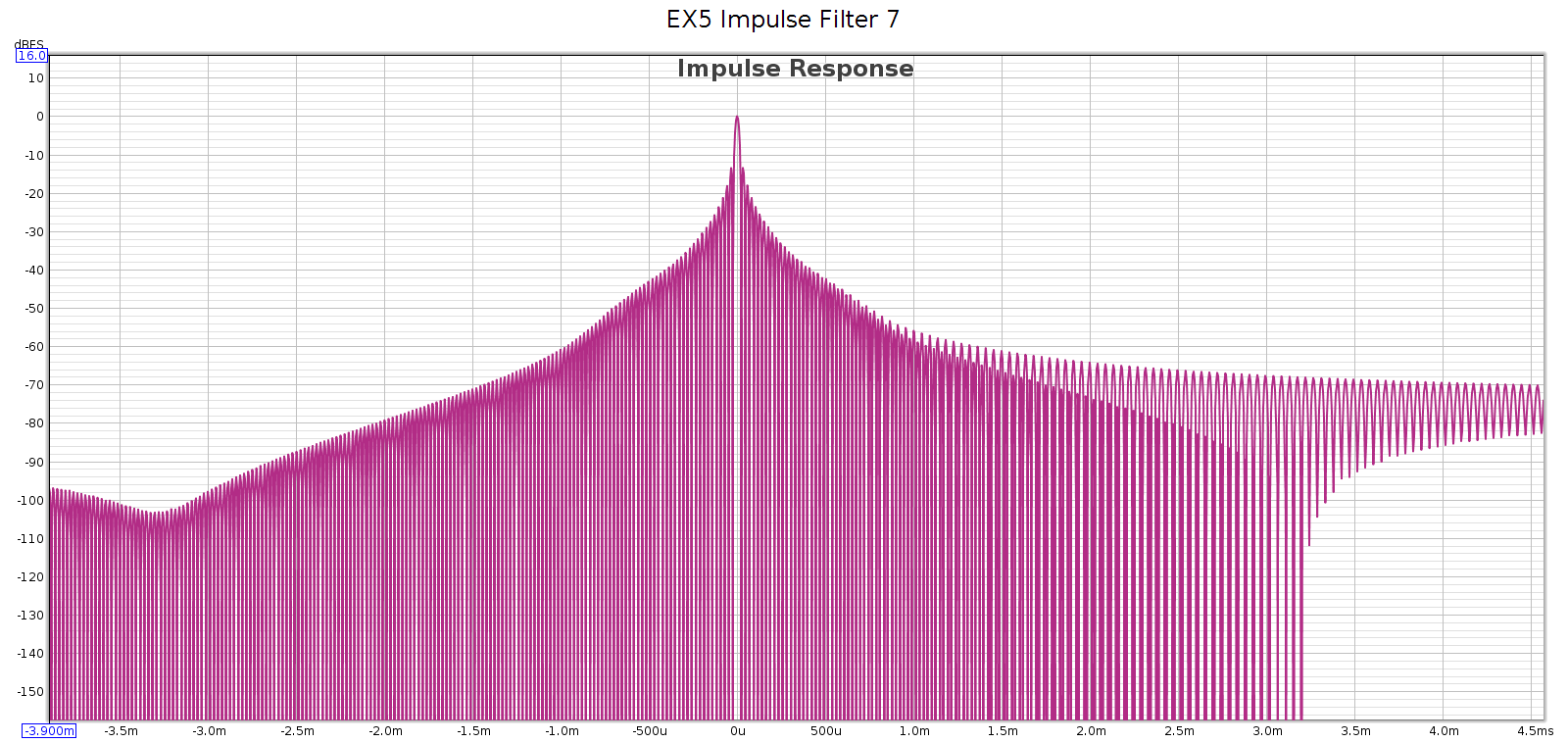
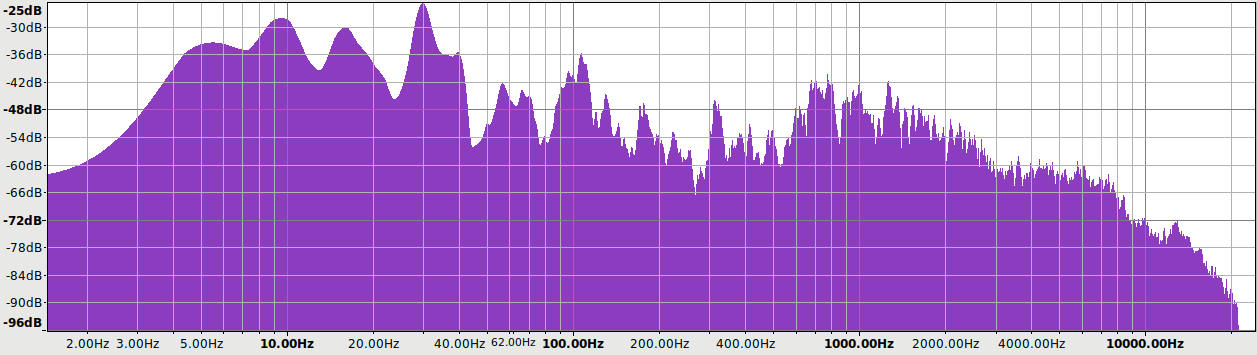
Comparison
The EX5 is such a great little device I couldn’t resist comparing it with my Corda Soul.
Frequency Response
The Soul has 2 user-selectable filters. Here’s how they compare with the EX5:
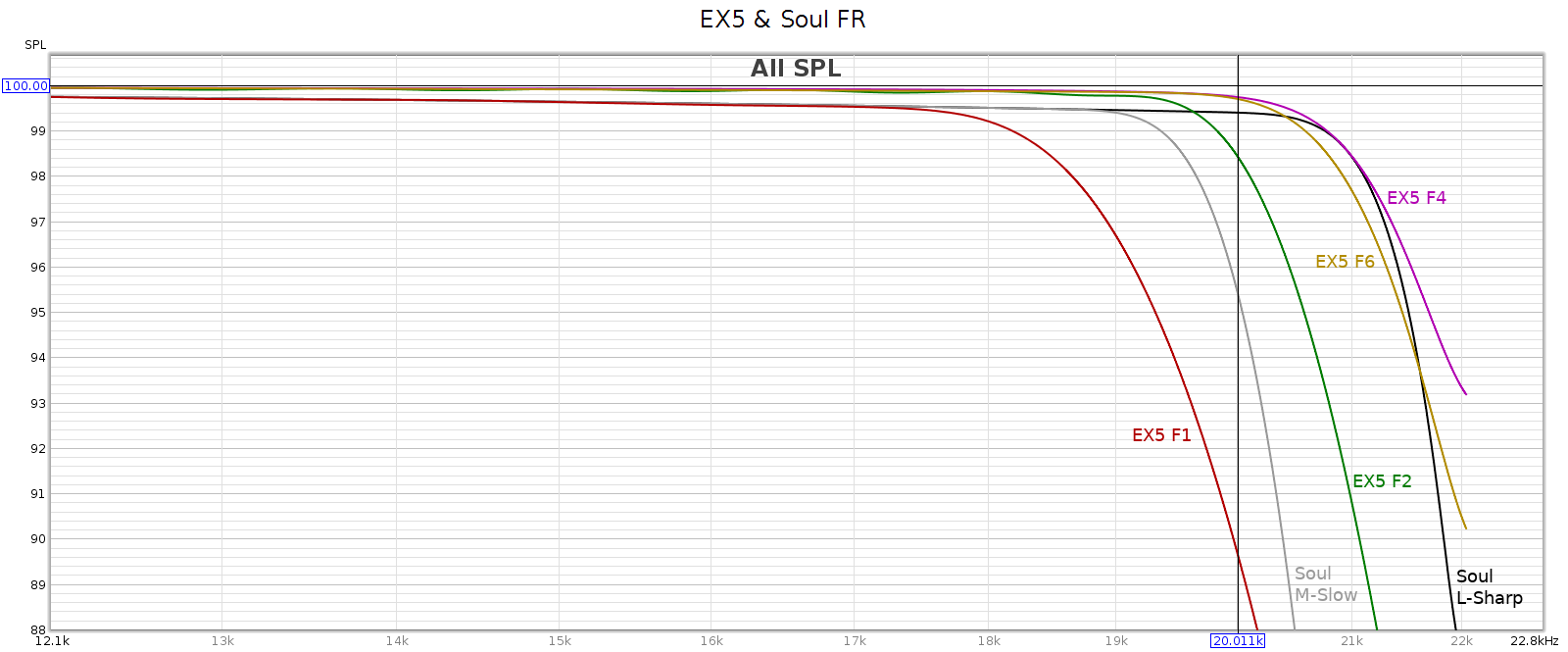
The Soul’s linear phase filter (L-Sharp) is the best shown. It is the flattest in the passband, perfectly smooth with no ripples, and fully attenuates by 24.1 kHz faster than EX5 #6.
The Soul’s minimum phase filter (M-Slow) is between the EX5 #1 and #4.