Summary
The Meier Audio Corda COUNTry is a unique little device:
- Equalizer, headphone crossfeed, reverb and other audio functions implemented in DSP (Digital Signal Processing)
- Inputs (digital only): USB, SPDIF coax and toslink
- Digital outputs: SPDIF coax and toslink
- D to A converter
- Analog output: single ended RCA (line level, volume controlled)
- Analog output: single ended 1/4″ headphone jack
Its purpose is to adjust or tailor the sound to listener preferences. You can use it in many ways, though they fall into 3 categories:
- Pure DSP upstream from your DAC
- Headphone amp
- Preamp
In the first case you already have a headphone amp or preamp and you only want the DSP features. In cases (2) and (3) the COUNTry is an all-in-one device. The COUNTry was originally designed for (1) without any D/A or analog outputs. Later, the D/A and analog outputs were added since they increase flexibility with minimal cost impact.
The COUNTry operates internally at a single fixed sample rate: either 96k or 192k (buyer’s option). Digital inputs are resampled (if necessary) to this rate. I received a 192k unit.
The COUNtry

As auditioned, tested, measured

Features
I’ll review the features in the order in which I might use them most myself. With some of the features, like crossfeed and reverb, I couldn’t imagine a way to measure them. However, I did use and listen to all the features, and found that each does what it says and the effect is easily audible.
Measurements
I measured the COUNTry using a PC running Ubuntu 18, an ESI Juli@ sound card, with Room EQ Wizard software. I also have an SMSL SU-6 DAC and a JDS Atom amp. The Juli@ SPDIF coax output went directly to the COUNTry. I measured it in 2 ways:
- COUNTry analog line level outputs to Juli@ analog inputs
- COUNTry digital SPDIF coax output to SMSL SU-6 DAC, to Juli@ analog inputs
This measured the COUNTry as an all-in-one device with D/A conversion and analog output, and also as a DSP-only device upstream from a separate DAC.
The Juli@ sound card is high quality, but it’s nothing like professional measurement equipment from manufacturers like Audio Precision. I can measure the basics (frequency response and distortion), but take the measurements that follow as directional guidance within the limitations of my equipment.
Equalizer
The equalizer’s 7 bands have equal octave spacing with frequency ratio of 2.5:1 or 1.32 octaves. They are symmetric and complementary, so they can be combined without ripple. A picture’s worth 1000 words, so here are frequency response graphs of the positive and negative ranges respectively, showing each control individually, and all combinations.
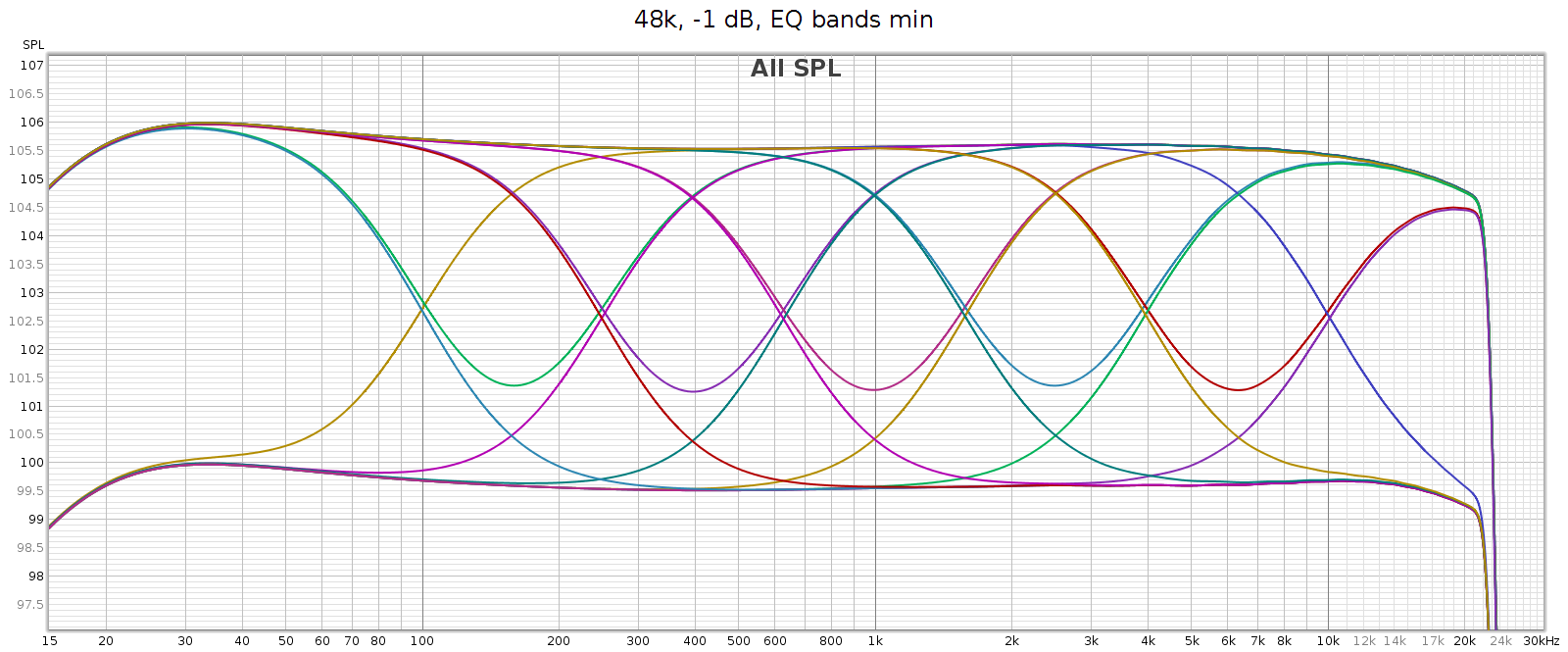
The manual says each band is +/- 6 dB, which is roughly true yet oversimplified. The max effect of any single band is +/- 4.3 dB. Two adjacent bands maxed together is +/- 5.7 dB. Three or more is 6.0 dB.
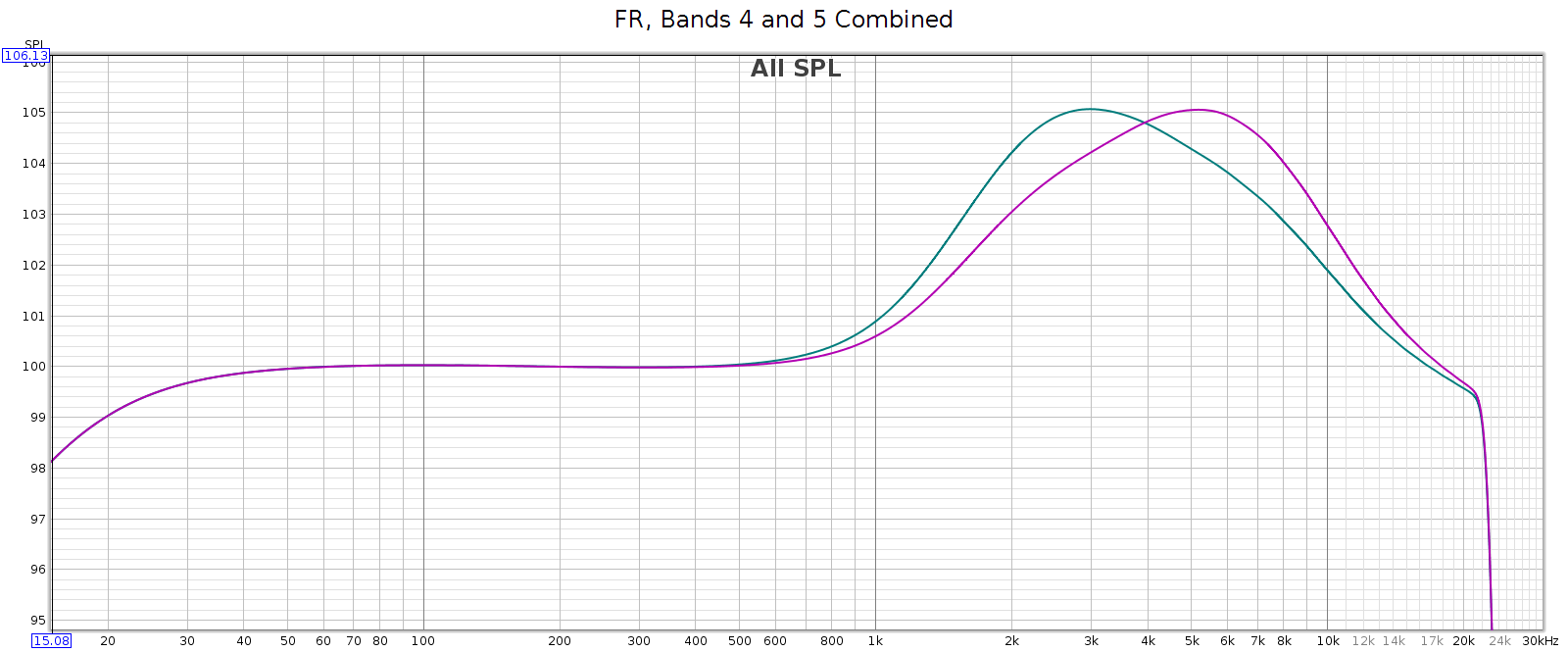
This enables adjacent sliders to be combined to form new bands. For example, consider sliders 5 and 6, centered at 2.5 and 6.2 kHz respectively. What I need to adjust the LCD-2F headphones is a slightly wider band centered at 4 kHz. And that’s exactly what I get when using both together, as you can see in the above frequency response graph. And, you can use different levels of these 2 sliders to shift the combined center frequency a bit higher or lower, to get a center frequency anywhere between 2.5 and 6.2 kHz. This makes the COUNTry’s EQ even more versatile than it appears.
For example, the following chart shows two combos: band 4 at max with band 5 at half (in teal), and band 4 at half with band 5 at max (in magenta). You can see the center frequencies are 3 kHz and 5 kHz respectively.
Regarding slider sensitivity: the following shows the center 1 kHz band at positions 1/4, 1/2, 1, 2, 3, 4, 5 and 6: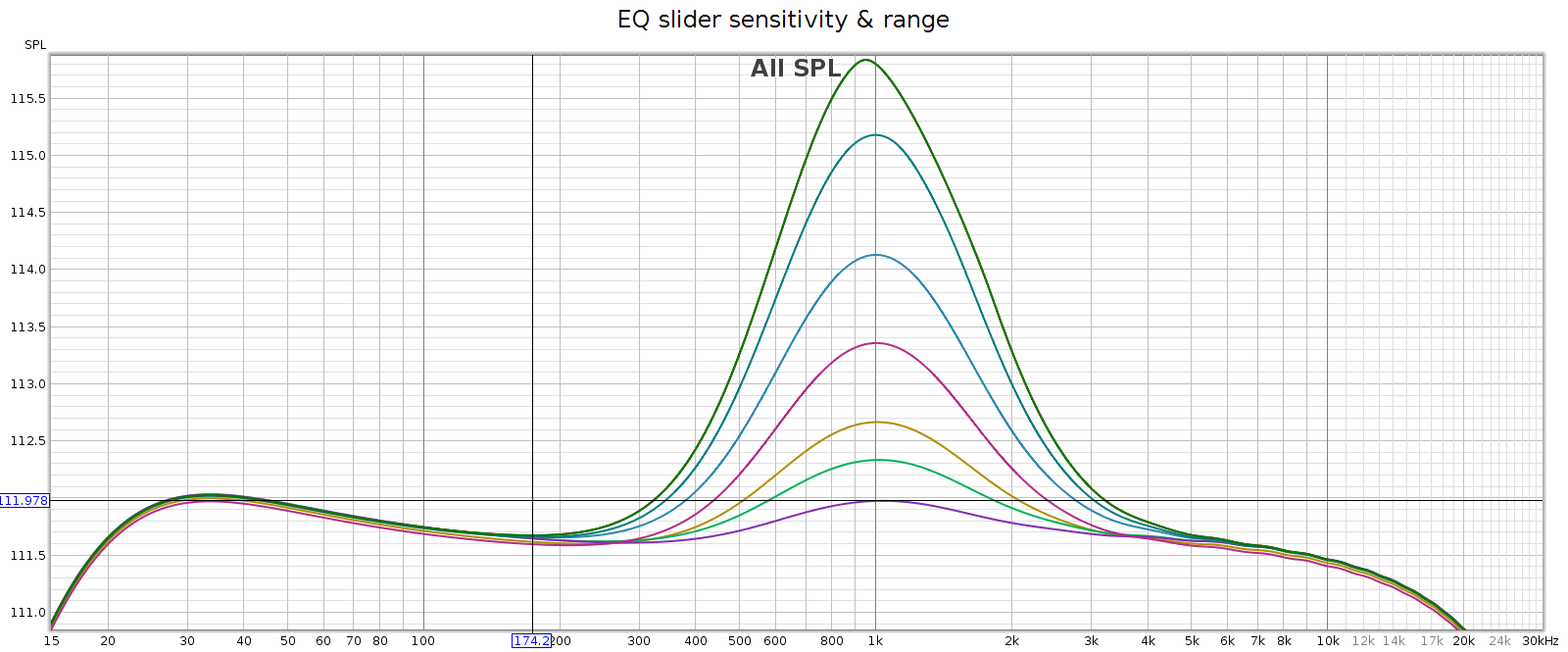
The slider effects are nearly continuous down to a fraction of a dB, allowing very small gradations. Each slider has 6 marked notches on each side (positive & negative), though only the center position is a tactile notch. The first 4 marks are about 1 dB each. The 5th mark is another 0.7 dB, and the 6th / last / max mark is the same as the 5th.
I like this design: it works like a conventional equalizer, but is more flexible. It’s a creative solution to an old problem.
Bass Boost
What: a gentle bass lift starting at 200 Hz and gradually increasing to + 6 dB at 20 Hz. This closely follows the bass attenuation of the popular Sennheiser HD-580 and HD-600 headphones, which is nice. It also mirrors the COUNTry’s bass attenuation in high gain mode, so use it if you want flat response in high gain. Its measured curve is shown twice in the following graph:
- The top red line versus the green line.
- The purple line versus the bottom orange line.
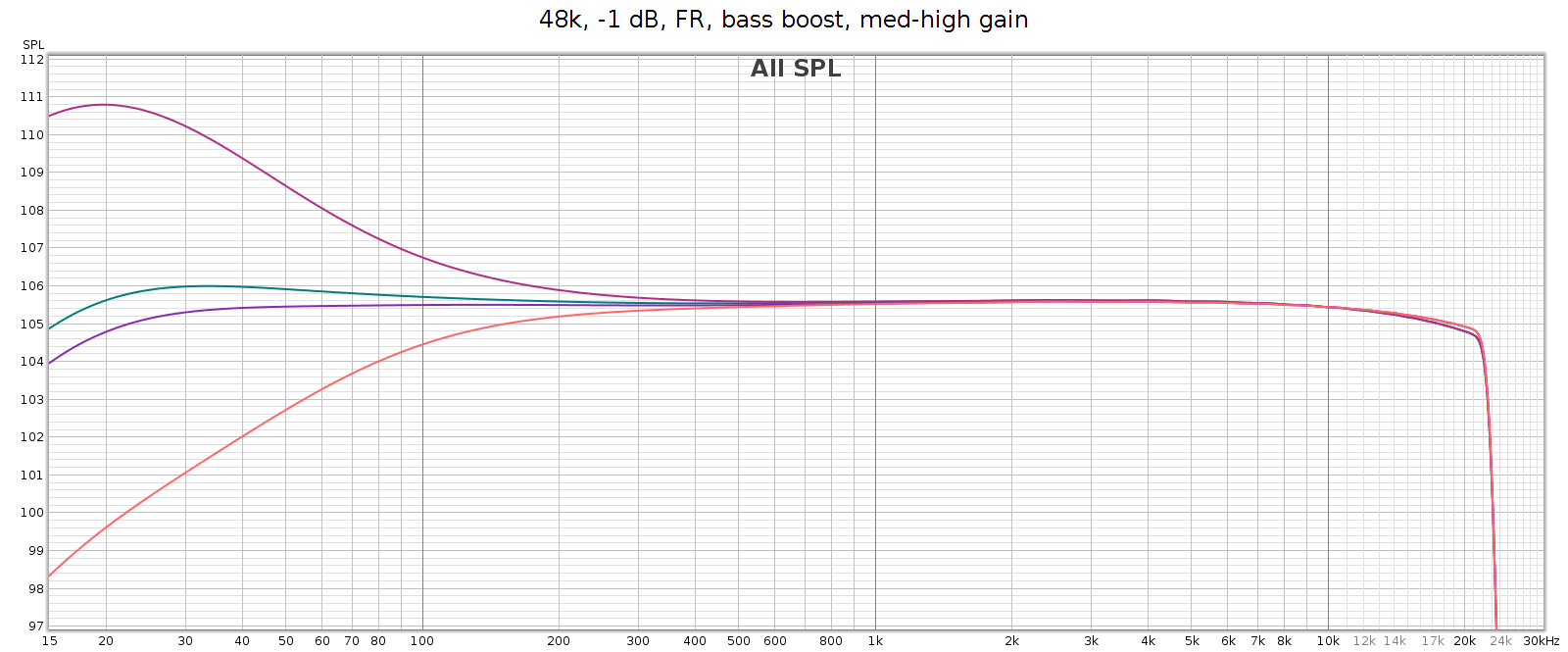
The manual says it’s a shelf boost with center frequency of 45 Hz and Q=0.5, which is true to the measured response. Q=0.5 is such a gentle slope that it is +1 dB as high as 120 Hz (evident in the above graph).
Stereo Crossfeed / Expander
Some recordings have sounds hard-panned to the left or right channels. This sounds wonky on headphones. Unfortunately, this was a common recording technique in jazz albums from the 1950s and 1960s – for example the classic Miles Davis / Coltrane album Kind of Blue. Crossfeed mixes a little of these sounds into the opposite channel, with a brief delay; it narrows the stereo separation. When listening to albums like this, it makes it sound more natural. The COUNTry has 7 levels of crossfeed (the Soul has only 5), and an 8th switch position that is mono (standard mono without crossfeed or delay). I don’t use crossfeed for normal listening, but it’s one of my favorite features because it’s so nice for those albums that need it.
Note: when clicking into mono, the sound suddenly becomes more dull. This effect is purely perceptual – the measured frequency response is exactly the same as in normal stereo.
Stereo expander does the opposite, making stereo wider. It’s intended for speakers but you can hear the effect somewhat on headphones.
Notch Filter
Many headphones have a resonance that causes a spike in frequency response in the 6k to 11k range. The COUNTry has a notch filter that cancels these spikes. Here’s the measured response of all 15 of the settings. It measures true to the specified Q=2.0, -6 dB.
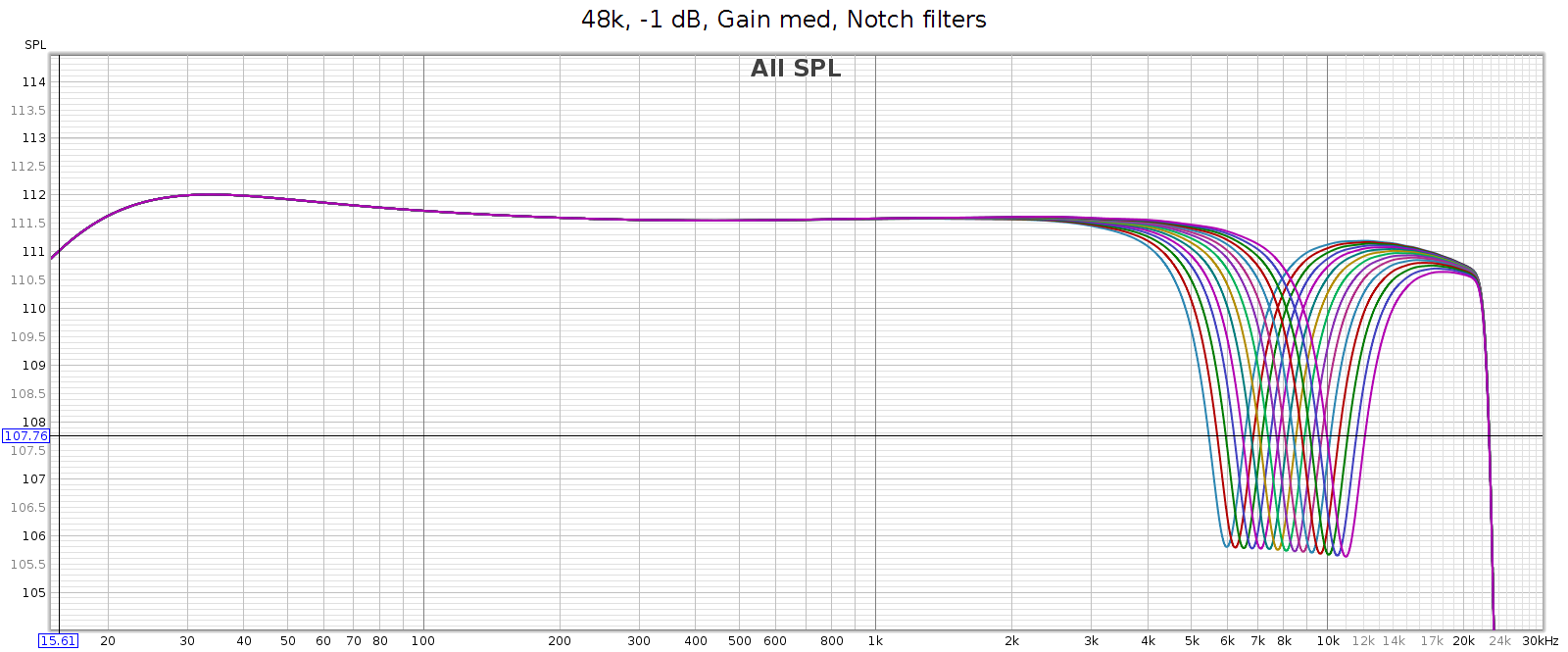
My Sennheiser HD-580 and Audeze LCD-2F don’t have such a spike, so I don’t use this feature. But the Sennheiser HD-800 does, as do many other popular headphones, making this a useful feature.
Reverb
This does exactly what it says: it adds reverb to the music. I’ve tried it with various recordings across a variety of musical styles from classical, to jazz, rock, etc. It’s not my cup of tea, as I prefer dry recordings. Yet this is a personal subjective thing. The reverb sounds natural and well implemented, and has 3 levels to play with.
Volume Control
The volume control feels analog but is digital, having perfect channel balance at every step from max to min. It also lights up an LED at certain exact positions: 0 (max), -6, -12, -18, and -24. This is useful for setting levels to avoid clipping when using DSP features.
Analog Gain
The COUNTry has 3 gain levels for its analog outputs: low, medium and high. Strangely, in high gain it attenuates low frequencies. The manual says this is to reduce excessive excursions of drivers at high levels. This doesn’t make sense to me, since high gain would be used for low sensitivity headphones or amps that need more voltage for the same sound level. And the COUNTry enables you to adjust the low frequencies if you want to. However, the bass boost switch exactly mirrors this bass attenuation, so if you are using high gain mode, turn on bass boost to get flat frequency response.
We’ve heard the mantra “the more gain, the more pain”. This is generally true, due to the constant gain * bandwidth of the transistors & opamps used in amplifiers. Because of this, the best approach is normally to use low gain whenever possible. That is, for a given loudness level, low gain at a higher volume position is usually cleaner than medium or high gain at a lower volume position. This also preserves digital resolution.
Note: This is especially true with conventional analog potentiometer volume knobs, which typically have better channel balance at high settings. However, the COUNTry's digital volume control has perfect balance at all settings. So that's not a factor here.
To test how the gain affects noise & distortion, I measured the COUNTry noise & distortion at each gain setting, with volume adjusted so that each had the same output level. Because the volume knob is digital, I couldn’t match the levels exactly, but I could match within 0.3 dB. More specifically:
- Low gain at volume -6 dB
- Medium gain at volume -16 dB
- High gain at volume -26 dB
Medium gain measured slightly cleaner than high gain, but only slightly. Low gain was about the same as medium gain. So with the COUNTry, the gain level you use doesn’t make a significant difference in distortion or noise. Just select the gain that matches the sensitivity of the downstream device the COUNTry is driving. Of course, remember that high gain attenuates bass so use the bass boost to get flat response.
CD De-Emphasis
As mentioned above, the 7 band EQ has a creative design that eliminates ripple across the bands and enables adjacent bands to be combined to shift center frequencies. However, the highest band (16 kHz) has a special feature. When set to the minimum, it applies the Redbook CD de-emphasis curve. It’s nice to be able to apply this manually since some old CDs use it, they sound much too bright unless it’s applied, and many aren’t formatted properly for DACs to recognize and apply it automatically.
However, the equalizer slider has no indication when this triggers. It triggers at the bottom position, but as you raise the slider, it moves a short distance before disabling de-emphasis and attenuating the 16 kHz band. If you want the most 16 kHz attenuation without triggering de-emphasis, you must do it by ear. Slide it all the way to the bottom, then slowly lift it until the sound suddenly gets a bit brighter. It would be nice to have an indicator that lights up when de-emphasis is activated. The LED on the 16 kHz hand is already used as a power indicator, but it would be nice to have it change color or blink when de-emphasis is activated.
Miscellaneous
The measured impulse response is symmetric and phase response is flat into the high frequencies, which means the COUNTry uses standard linear phase filtering, rather than minimum phase.
The case and knobs are constructed in a manner that appears easy to disassemble and service. It’s good to see this exception to our modern age of cheap disposable equipment. I did not test this by opening the unit, since it is just a loaner.
Support is excellent. You can contact Jan Meier of Meier Audio directly on the company website or on Head-Fi. He is responsive, knowledgeable and helpful.
Usage and Build Quality
The COUNTry is a nice little device with an unusual look. It’s an “old-school” look and feel with physical knobs and LEDs instead of a display screen with menus. It has high build and parts quality.
Some of the indicators are a bit obscure but they become intuitive as you use them. For example, the digital sample rate display is done with 2 LEDs. One for the base rate (32, 44, 48) and another to indicate a multiplier (2x or 4x). Another LED lights up when the volume control is exactly at certain positions: 0 (max), -6 dB, -12 dB, -18 dB and -24 dB. This is a nice guide for setting precise levels.
The rotary switches make a solid “snap” and feel like professional test gear. The toggle switches are similar. The EQ sliders feel like potentiometers, smooth with just the right amount of friction. The COUNTry is fully digital, so it detects the slider position and translates to a digital value. There is a tactile detent for the center position, but no others indicating when it’s shifted from one value to another. The controls feel good to use.
The headphone jack is seriously robust and overbuilt. The back panel connectors are not as robust but still feel solid. This makes sense as the headphone jack is likely to be plugged & unplugged much more often than the rear connectors.
Sound Quality (Subjective)
OK so what does it actually sound like? I listened on my Sennheiser HD-580 headphones. They are over 20 years old, but have fresh pads and I recently tested them with a MiniDSP EARS rig. They still have measured performance like new. I also used Audeze LCD-2F headphones (also tested & measured). The sound source was my PC with its ESI Juli@ sound card, and lossless FLAC files at bit rates ranging from 44.1 to 192. The Juli@ card coax SPDIF output routed to the COUNTry. I routed the COUNTry’s SPDIF digital output to my SMSL SU-6 DAC and JDS Atom headphone amp. With this setup, I could plug the headphones directly into the COUNTry, or into the JDS Atom. This enabled me to test the differences (if any) between the COUNTry in pure digital mode, versus its D/A and analog outputs.
I level matched by playing white noise, routing the analog outputs to my Juli@ card and measuring the level. With the JDS Atom’s analog volume knob, this enables level matching to about 0.1 dB.
In a word, the COUNTry sounds just a bit brighter than the SU-6 + JDS Atom. I first noticed this with music, and confirmed it with pink noise, which is a useful test signal for hearing subtle differences in frequency response. This brightness was unexpected, since the COUNTry’s analog frequency response has a slight bass boost and treble cut. However, the brightness sounds like it’s in the upper mids / lower treble, rather than in the highest frequencies. Loud parts with many instruments playing (like a symphonic crescendo) are slightly less resolved on the COUNTry analog output, compared to the SU-6 + JDS Atom.
Subjectively, the COUNTry analog output has a good clean sound across a variety of music with no obvious issues or artifacts. Though it’s not state of the art in terms of linearity, smoothness or detail – nor was it intended to be. Think of the COUNTry analog outputs as a sonically competent add-on feature. The COUNTry digital outputs are more transparent.
When you plug in headphones while the COUNTry is playing, it sometimes emits two loud CLICKs in the headphones, then pauses for about 1 second before the music starts. Inserting the headphone plug quickly usually avoids this. Meanwhile, the line level outputs are always playing and do not pause or CLICK. If you power on the COUNTry while it has musical input, you get a single loud CLICK then the sound starts playing in the headphones.
Anomalies
Frequency Response
Analog frequency response is not quite flat, and different in low (blue), medium (green) and high (red) gain. Medium gain has a 0.5 dB lift in low bass, and high gain has a 6 dB drop in low bass. All modes gently taper high frequencies, reaching about -0.6 dB at 20 kHz.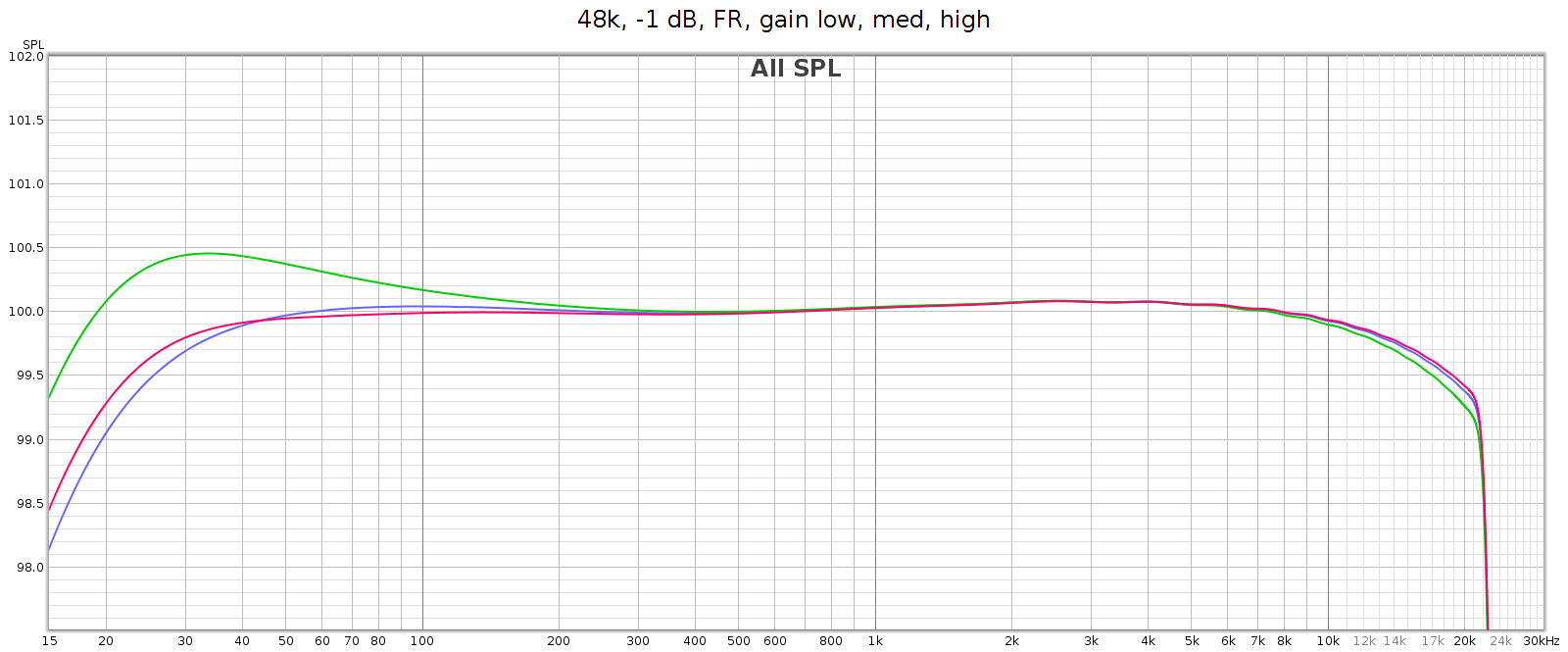
Note: in the above high gain curve (red), digital bass boost was applied to flatten the response. The uncorrected response is shown in another graph below.
Why the frequency response differences at different analog gain levels? This is due to the Meier Audio FF or Frequency Adaptive Feedback. It attenuates low frequencies in the digital inputs, then boosts them back to flat again in the analog outputs. This means the attenuation curve (implemented in DSP) must match the boost curve (implemented in passive analog components). Meier Audio optimized this matching at low gain, since they expect that will be most often used. The purpose of FF is to frequency shape and optimize DA conversion and the gain-feedback loop, so it is only used for the analog outputs, not on the digital outputs.
As mentioned above, in high gain the frequency response attenuates bass beginning at 200 Hz, gradually reaching -6 dB at 20 Hz (this is noted in the manual). The COUNTry has a DSP bass boost that applies the exact reverse of this. So if you want flat response in high gain mode, turn that on (as it is in the above graph).
Let’s take another look at the bass boost frequency response graph shown earlier. From bottom to top:
- Orange is high gain
- Purple is high gain with bass boost activated
- Green is medium gain
- Red is medium gain with bass boost activated
The COUNTry’s digital output is smoother and more linear, but still has gentle HF attenuation reaching -0.6 dB at 20 kHz, and even gentler LF attenuation about -0.2 dB at 20 Hz. We see below that this slight attenuation happens in the digital domain. This graph shows the digital output with all sampling rates on top of each other:
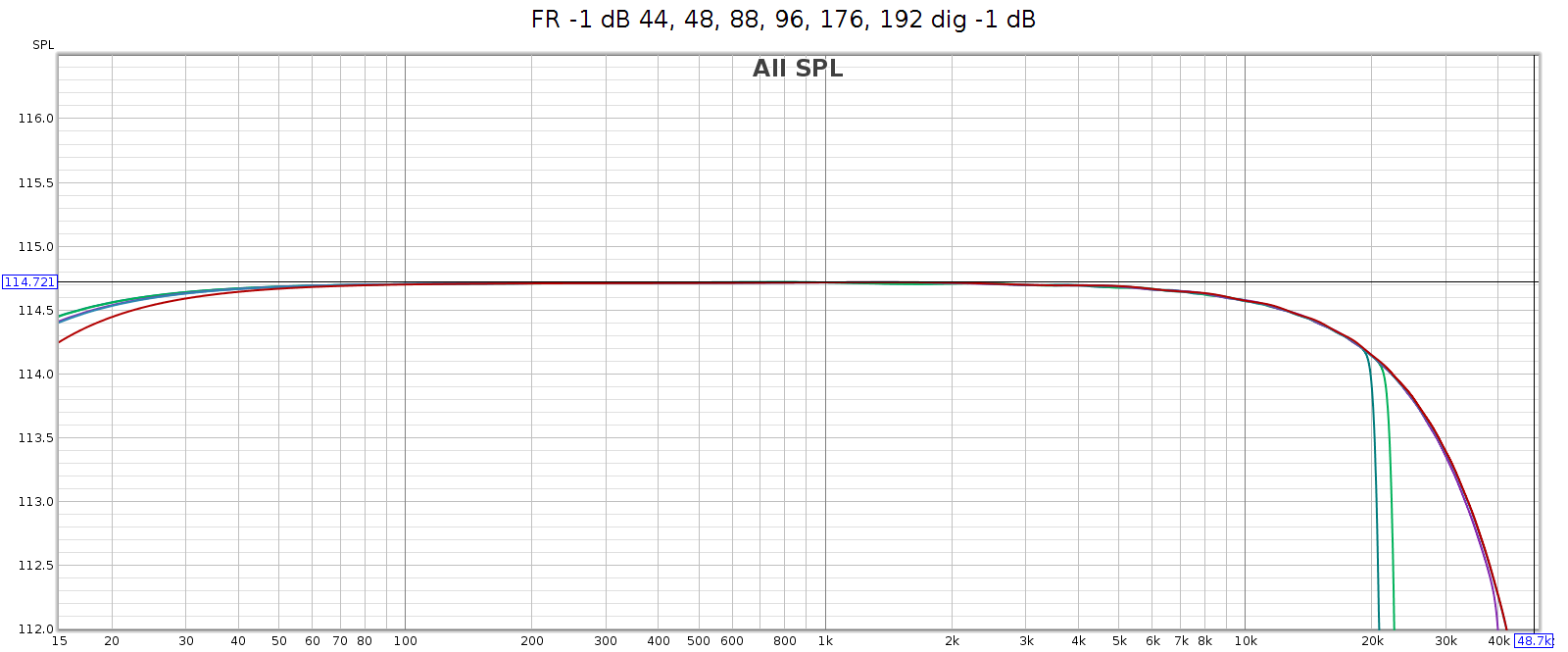
Noise at High Sample Rates
At high sample rates (176.4 and 192) the COUNTry has a lot of high frequency noise. This is unexpected and unusual, so I tested in several different ways:
- Analog outputs
- Analog outputs at lower levels (-6 dB, -12 dB)
- Analog outputs with lower digital input levels (to -48 dB)
- Analog outputs with input from my phone (USB Audio Player Pro) in bit perfect mode, instead of from my computer (ESI Juli@ sound card)
- Digital outputs
- Digital outputs at lower levels (to -48 dB)
It measured the same in all cases. This suggests the issue is not in the D/A conversion or analog stage, but in the DSP.
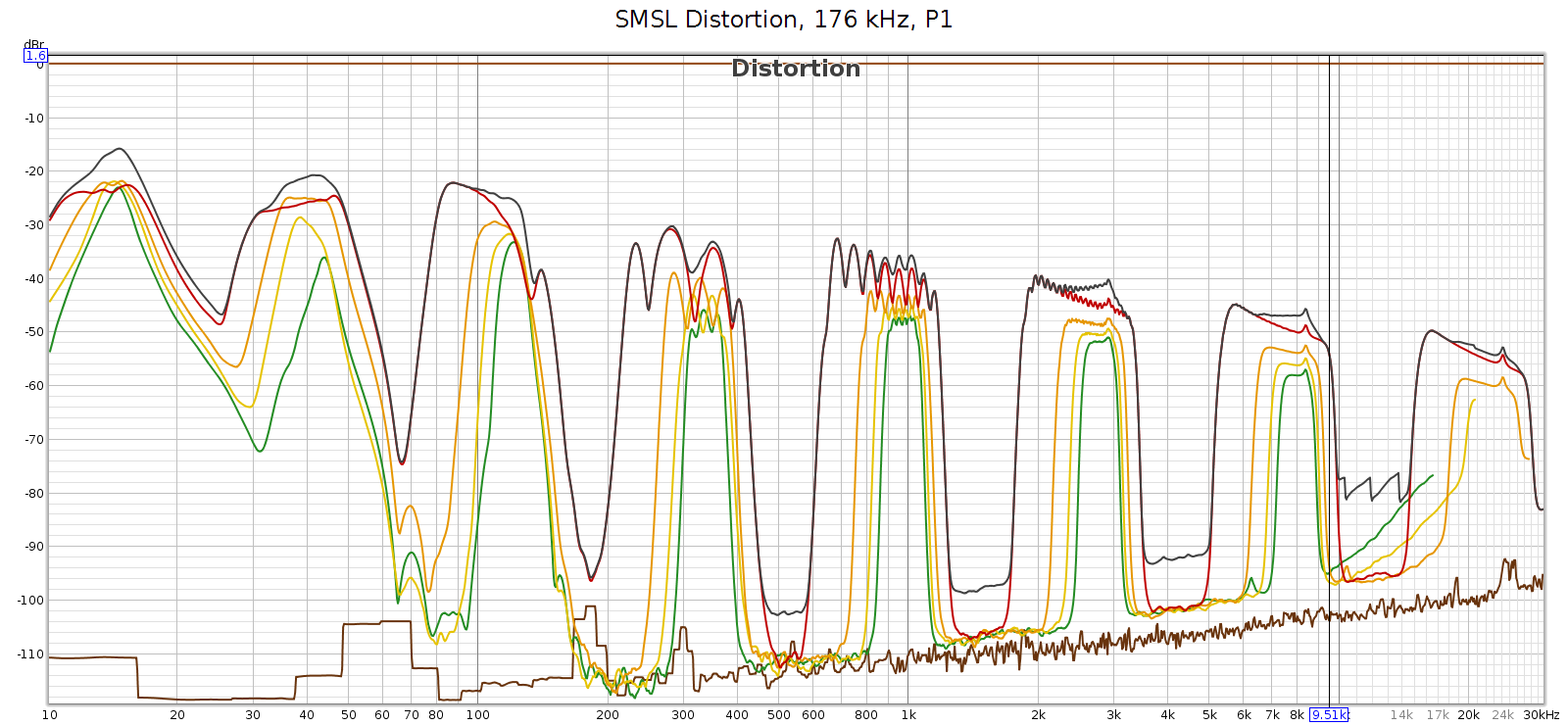
Here’s what that noise looks like at 176.4 kHz. Actually, in the graphs below it looks like distortion rather than noise, but more on that later. The horizontal line at y=0 dB is the sweep signal. It is not really at 0 dB, but this is relative to facilitate reading the levels. The brown line is noise. The black line is THD. The colored lines are 2H, 3H, etc., which sum to the black line.
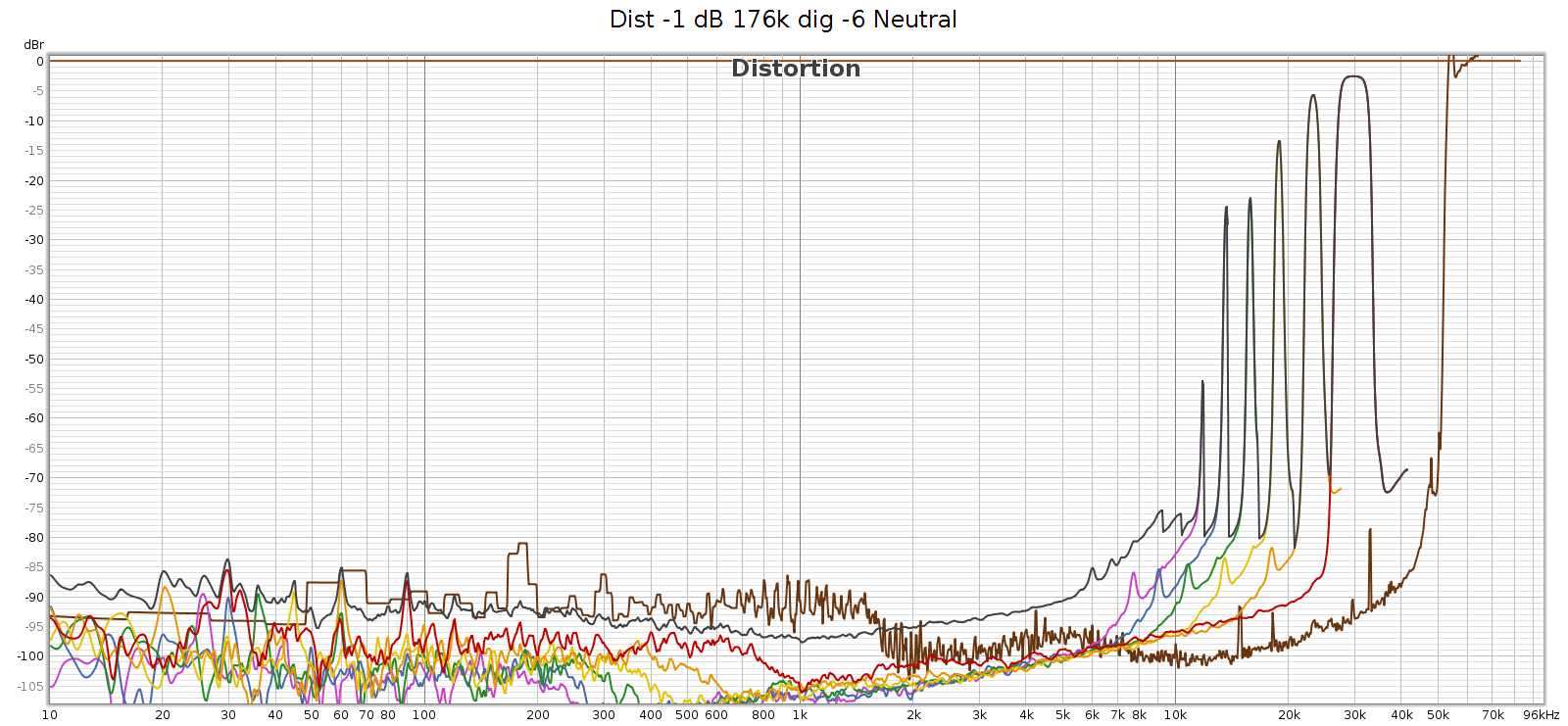
At 176.4k, it’s clean up to 11 kHz and that first distortion spike is at 11,960 Hz. This is inaudible since it’s 7th harmonic so the distortion tone is at 11,960 * 7 = 83,720 Hz. However, these distortion spikes are big enough that their intermodulation (IM) differences are in the midrange. They are spaced 1-3 kHz apart, which puts the IM smack-dab where our hearing is most sensitive to it.
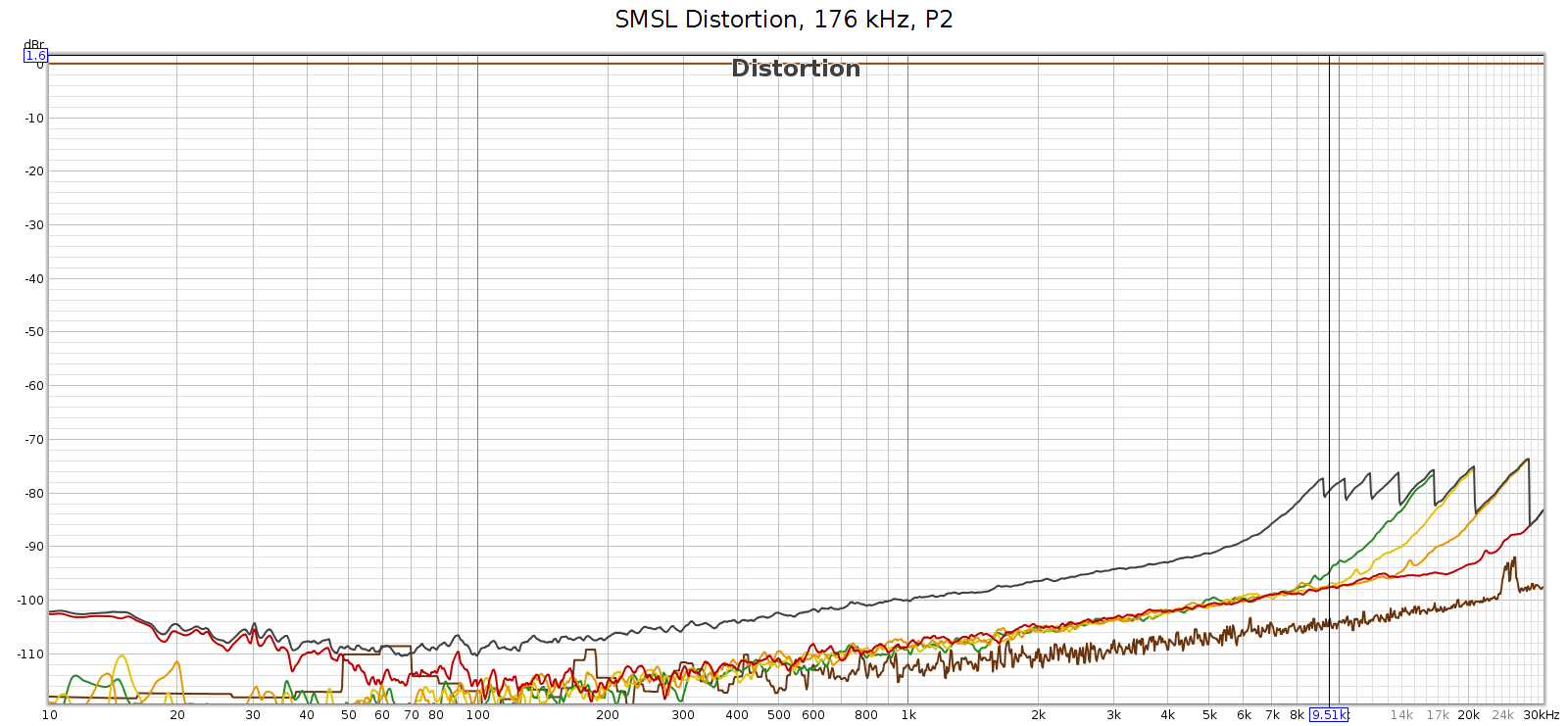
Here’s what it looks like at 192 kHz:
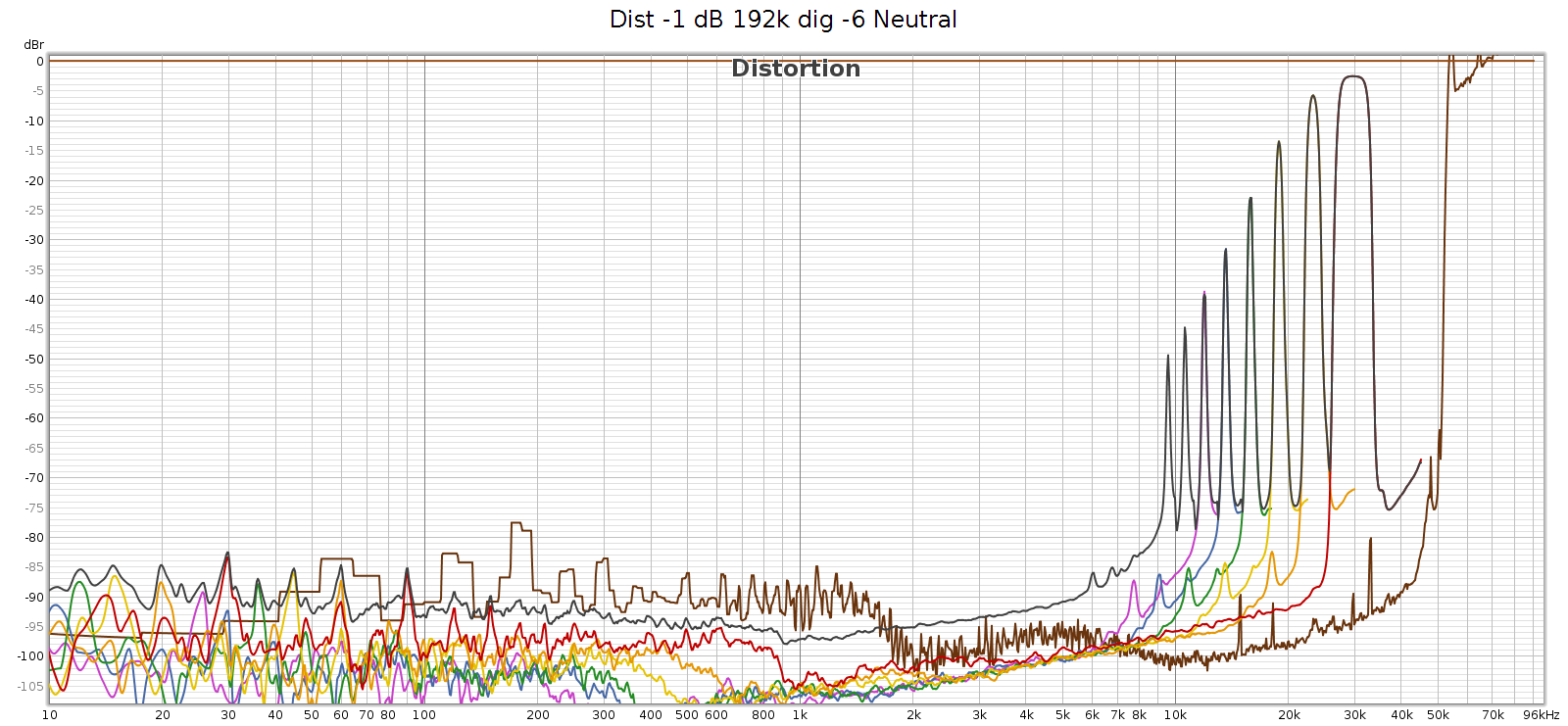
At 192k we have a similar situation, first distortion spike at 9,580 Hz, which will be inaudible since it’s 9th harmonic so the distortion tone is at 9,580 * 9 = 86,220 Hz. The 7th, 6th, and rest of harmonics are the same as at 176.4k sampling. And as above, the IM difference tones will be in the midrange.
Two interesting observations about these frequencies:
- They are exactly the same at 176.4 and 192 kHz. This suggests it is noise, not distortion – it’s not correlated with the signal.
- They all point to noise in the same region: 53 to 86 kHz
More precisely:
- H9 @ 9,580 Hz means a frequency at 86,220 Hz
- H8 @ 10,620 means 84,960
- H7 @ 11,960 means 83,720
- H6 @ 13,640 means 81,840
- H5 @ 15,870 means 79,350
- H4 @ 18,940 means 75,760
- H3 @ 23,320 means 69,960
- H2 @ 30,000 means 60,000
Here’s my speculation as to the root cause. Something in the COUNTry (perhaps a switching power supply?) is operating at 65 kHz. This is not fully suppressed or filtered and is leaking (somehow?) into the digital data. At sample rates 96k and lower, it’s above Nyquist and thus digitally filtered. But at 176.4 and 192, it’s below the Nyquist limit of 88.2 and 96 kHz respectively, so it is in the passband. Thus this power supply switching noise appears as harmonics of the given lower frequencies. If so, then it’s not really distortion, it’s noise.
Wherever the source of this noise, it’s interesting to study it closer. I created another graph below for this. Noise goes through the roof (literally – greater than 100% or louder than the fundamental) with spikes at 54.6 and 65 kHz. This noise profile and the spike frequencies are exactly the same at 176.4 and 192 kHz, so it’s independent of sampling frequency. It looks like this noise is what the graph (incorrectly) shows as distortion. Each of the N harmonic spikes is simply that same noise frequency divided by the next larger number (2nd, 3rd, 4th, etc.). Note that noise above the 0 dB line is not a bug. The spike at 65 kHz at +10 dB means it’s 10 dB louder than the signal.
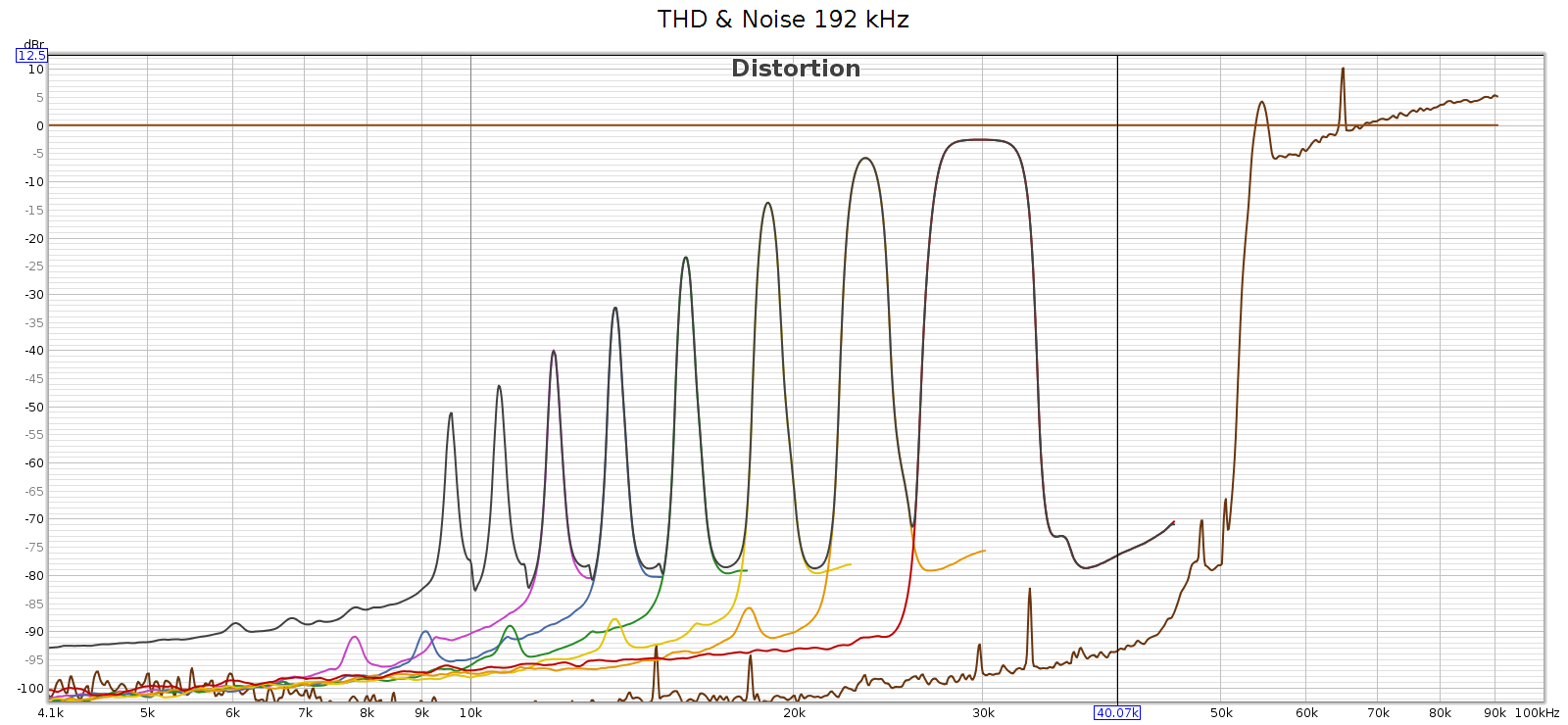
In case this noise were caused by the high level of the digital signal (even though it wasn’t clipping), I ran another sweep at -48 dB. The noise profile looks the same:
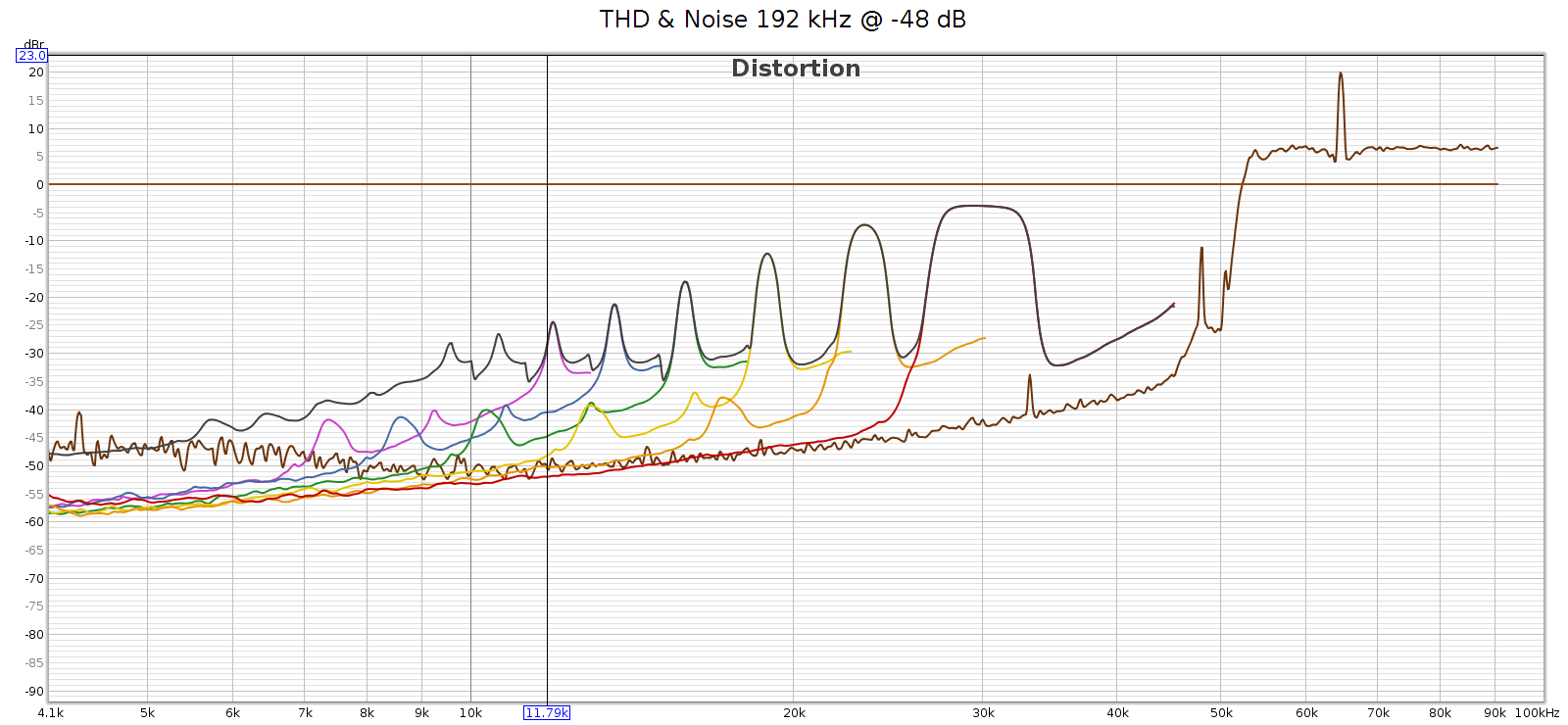
In short, the noise is a constant level, and a constant frequency spectrum. It’s independent of the sample rate and of the input signal. This suggests it’s noise not distortion.
I said earlier that I was speculating – let me clarify. What is not speculation, but observation, is a lot of supersonic noise at high sample rates. My speculation is toward the root cause. I love a good puzzle and this explanation fits the observations. But I don’t really know what is causing that noise. So let’s set root cause speculation aside…
For comparison, here’s the COUNTry distortion and noise at 96 kHz, measured at the analog outputs at medium gain: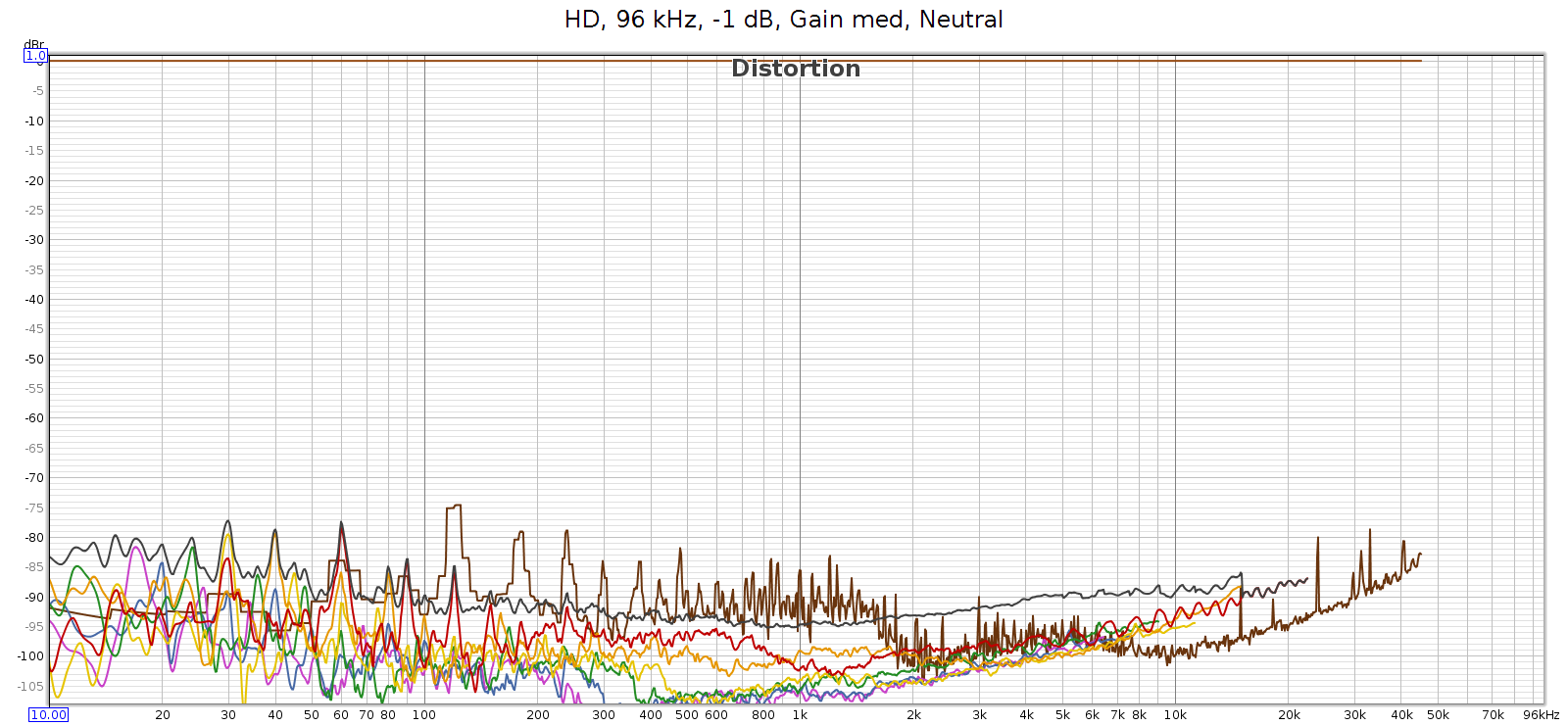
BTW, see that drop in noise & distortion from 700 to 2,000 Hz? I’m guessing this is the previously mentioned FF at work.
Here’s the distortion and noise of the measuring system, my ESI Juli@ sound card in loopback:
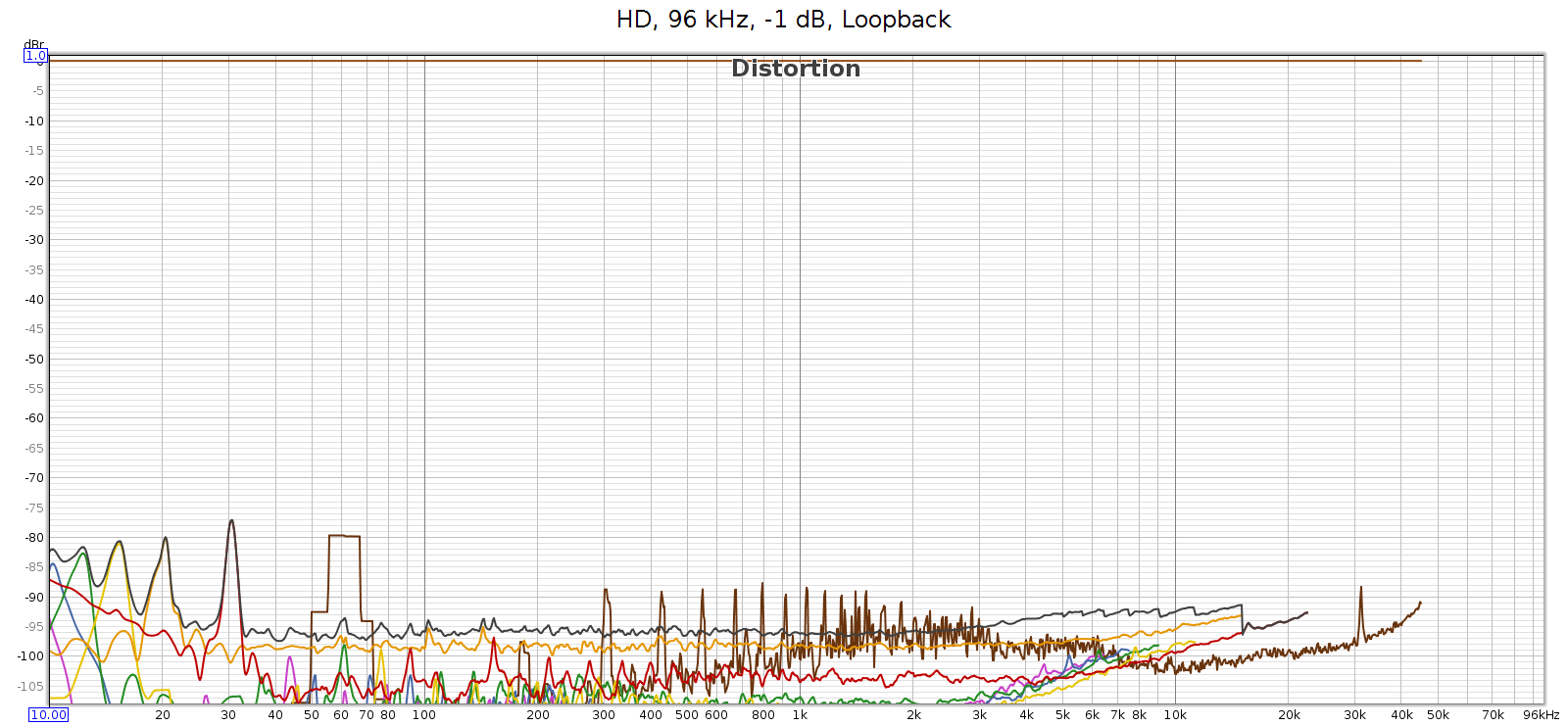
This typical of all sample rates 96 kHz and lower. So the COUNTry’s D/A and analog output is pretty clean – just a bit higher than the loopback connector, but not much. This should be well below audible levels.
Finally, I used Audacity to under-sample the 192 kHz test signal to 96 kHz, then played it through the COUNTry. The output looked clean, just like the 96k signal above. As expected.
Just in case the issue was with the 192 kHz tone itself, I measured how the SMSL SU-6 reproduces that test sweep signal, directly without the COUNTry. You can see those rising harmonics, but they cut off around -80 dB. This is the inherent noise and distortion of the Juli@ card’s analog input and A/D converter.
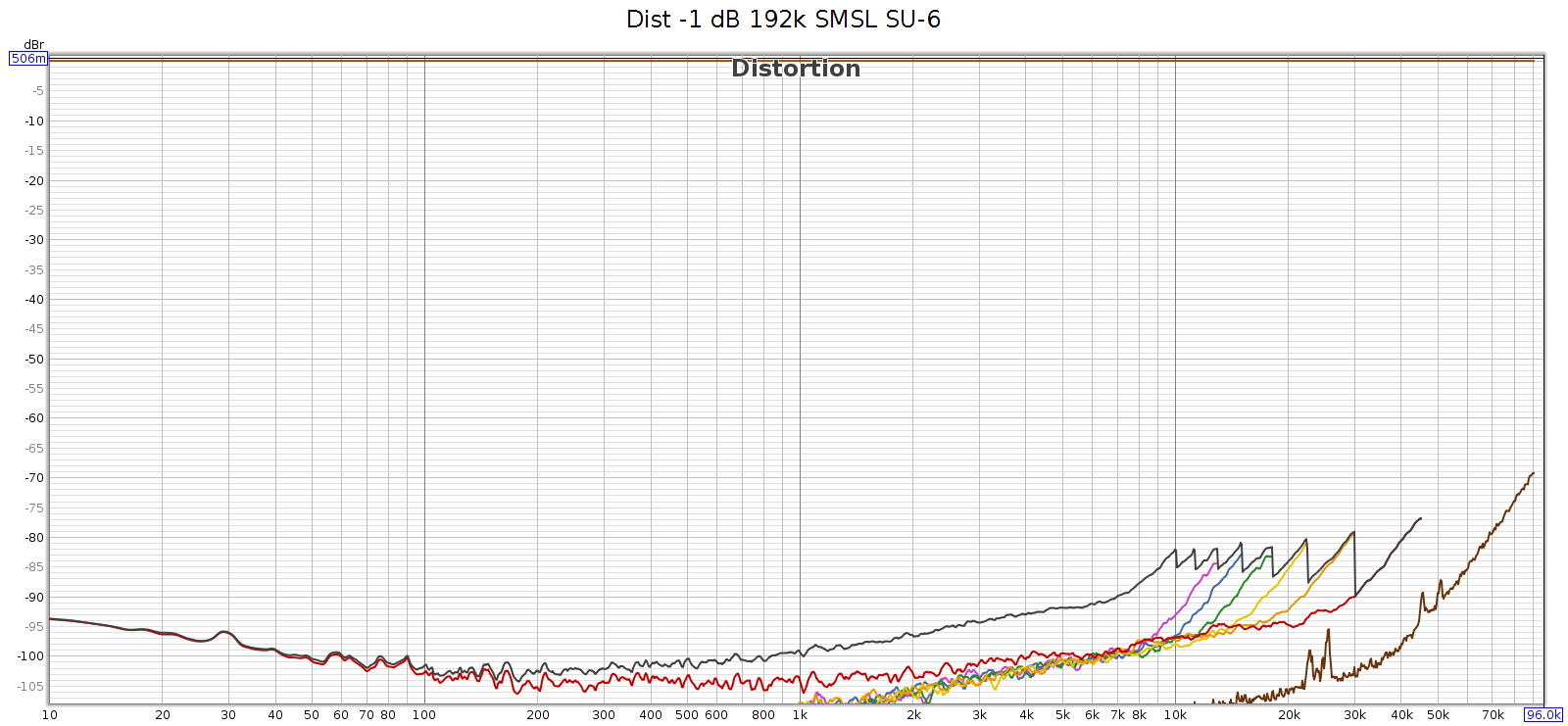
Conclusion
The COUNTry is a unique device. At 1 kilobuck it’s rather pricey, but considering its functionality, as an all-in-one device it replaces several others: DAC, amp and EQ with DSP. If you bought these separately, the total cost might be similar. And the COUNTry’s DSP features are unique and well implemented – you might not be able to find such a flexible EQ, or DSP with crossfeed or reverb. It’s built to last and the sound quality, both measured and subjective, is quite good if not state of the art. Used in purely digital mode, it should be sonically transparent, at least up to 96 kHz.
Meier Audio sent me one on request because I was curious about it. I don’t get to keep it. Yet over an extended trial using it nearly every day, here’s what I like best about it:
- The flexibility of the EQ (shifting center freqs by combining adjacent bands) enables me to match the LCD-2F and HD-580 headphones, and most others.
- The crossfeed is nice especially with albums having hard-panned L-R stereo separation.
- Flexibility to be an all-in-one device or run in digital-only mode.
- Works with my various audio systems with no observed software/firmware bugs.
- Good quality, seems built to last with good support.
Suggestions for improving the COUNTry:
- Fix the HF noise/distortion issue at high sampling rates.
- For improved transparency, make a version that run DSP at the native sampling rate of the source without resampling.
- If native rate processing is not possible, then over or under sample at integer multiples. Example:
- Implement all internal functionality at 2 rates: 88.2 & 96
- Input at 44.1, 88.2 and 176.4 process at 88.2
- Input at 48, 96 and 192 process at 96
- Provide an indicator when CD de-emphasis is activated (perhaps change the color of the 16k EQ band).
- Eliminate the bass attenuation in high gain mode.
- Sure you can normalize it with bass boost, but better to give it flat response like low & medium gain.
- Not really an issue for me, since low gain is plenty for my headphones.
- One of the nice things about the COUNTry is that due to the physical knobs you can see all the modes at a glance. But the knob detents are hard to see. If I owned this device I’d fill the detent notches with white paint.
Of the above, the the only thing holding me back from buying one for myself is the first 2 items. Eliminating the high frequency noise and not resampling might also improve the clarity / transparency / sound quality.
Meier Audio makes another version of the COUNTry that resamples everything to 96 kHz instead of 192 kHz. This 96k version has a more complex implementation of bass boost, called bass enhancement. It’s quite an interesting feature that leverages the psychoacoustic phenomena known as the “false fundamental”. As cool as that is, this 192k version has certain advantages, even if one doesn’t care about the difference in sample rate:
- Bass boost exactly offsets the analog bass attenuation at high gain. The 96k version has no way to do this, since it replaces boost with enhancement.
- Bass boost closely offsets the bass attenuation of several headphones, especially the Sennheiser HD 580/600/650/800 models.
Note that neither of the above reasons has anything to do with 96k versus 192k sample rates. In my opinion, 192k offers no real advantage over 96k because whatever advantages are gained from rates higher than the 44.1k CD standard, are fully realized at 96k.
Update: Apr 2023
Meier audio has a new version of the COUNTry:
- Performs all DSP at the native sample rate (32, 44.1, 48, 64, 88.2, 96, 128, 176.4, 192)
- Digital-only mode has no resampling, should be fully transparent
- D/A conversion is always done at 96k, since the WM8716 chip is optimized for this rate
- The analog audio output is resampled to 96k before D/A conversion
- Equalizer step sizes are 0.5 dB resolution
- Reverb replaced with 3 levels of bass boost (50 Hz shelf, Q=1.0) +2, +4 and +6
- The original bass boost (45 Hz shelf, Q=0.5, +6 dB) is retained, and can be applied in addition.